Today, Machine Learning appears constantly in the specialized press, and sometimes in the most general, with new and surprising applications, and everyone “talks about it.”
The aim of this post is that the unedited reader can acquire a high-level view of this hot topic, including a formal definition of machine learning (which we will give at the end of the next blog about the topic).

Artificial Intelligence
Let's start, to understand, by Artificial Intelligence. For most of us, precisely defining the term "intelligence" can be complicated. overall, we all have our own "intuition" of what intelligence is (although we cannot explain it precisely); and there are formal definitions within different disciplines: psychology, philosophy, neurosciences, informatics...).
If we go to the dictionary of the RAE, we will find the problem that the definition of intelligence depends on other terms that, in turn, need to be defined and are also difficult to explain precisely ("understand", "reason", "solve a problem", ...) and we will end up in what in software development is called cyclic dependencies (a mess of definitions that depend on others and each other, far from simplicity and precision).
Artificial intelligence can be defined informally as the ability of software to reason and learn like humans. Reader, "whatever it means, ... "but you know what I mean".
Vision (segmenting and recognizing objects from the photosensitivity of our cells of cones and canes), learning to speak or write, translating from one language to another, driving a car, learning to walk, painting a picture or composing music, playing chess, etc. are human activities that are normally recognized as "intelligent".
Applications that we can carry and run on our smartphone (such as translators and assistants), or on servers on the cloud as for the recommendations of products to buy, lower the oven temperature through domotics using voice, the automatic labeling of the content of a photograph, cars freelancers, robots that learn to walk and overcome obstacles, etc. they fall within, therefore, the intuitive definition of applications (they are executed today by machines) and of intelligent (since they are similar tasks to those that in the previous paragraph we have recognized as intelligent for humans).
However, from the learning that a three-year-old can do, able to distinguish an elephant from a lion in a photo, or learn to speak correctly and recognize and execute the commands that are communicated to him (at best, I mean as a self-sacrificing father), to the reasoning that is necessary to define a quantum theory of gravity (to give an example of a current problem that humans have not yet been able to solve after decades of trying), there is a long way to go.
Today, we are at the historical moment in which we can design software with a very high learning capacity, but still far from tackling "hard” problems on their own (... but everything will come in time).
Automatic learning
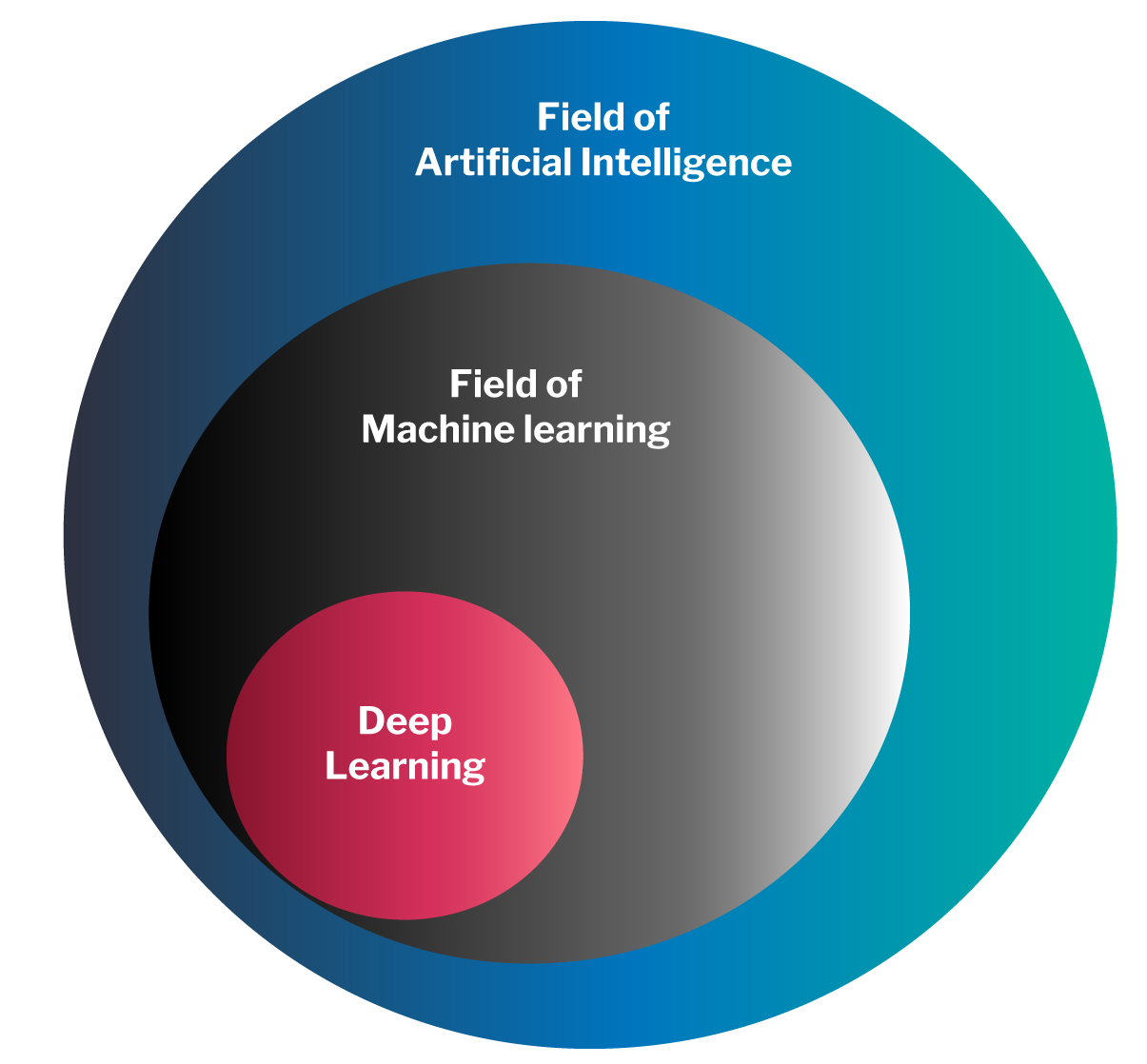
Machine learning (ML) is a specific branch of artificial intelligence: ML is artificial intelligence, but not all artificial intelligence is ML.
ML, however, is the branch of artificial intelligence that is related to the vast majority of intelligent applications that lately flood us and, most notably, deep learning based on neural networks.
Peter Xenopoulos, Data Scientist and doctor of Computer Science, reusing Dan Ariely's 2013 Twitter about big data, said in 2017:
“"ML is very similar to teen sex:
- Everyboy talk about it.
- Only some really know how to do it.
- Everyone thinks everyone else does it.
- Therefore, everyone claims that they are doing it.”
Given that we can consider that, today, the ICT industry (in general) is at an early stage, but adult in big data , we can do an exercise in extrapolation and forecast that the industry (in general) will not abandon its teen years in ML until at least 2023.
"In general," in my previous paragraph, means "the majority." Obviously, as Xenopoulus comments, “some know how to do it”, but they are generally universities and ID centers, “blue chips” ICT with ID departments (such as Google, Amazon, IBM ,…) and very innovative companies, usually start-ups, spin -offs from universities / research centers and that, in many cases, are quickly absorbed by blue chips (through heavy funding) as soon as they have an innovative ML application and with the prospect of generating business.
A concrete example of ML: The challenge Imagenet
Up to this point we have not yet given a formal definition of machine learning (nor will we do it in this first blog, we will have to wait for the second...). In my opinion, the best way to understand a formal definition comes after understanding a concrete and real example.
The example chosen is the Imagenet challenge. Imagenet is a repository that currently has 14,197,122 color images contributed to by people around the world (led by research centers such as Stanford and Harvard). These people have contributed not only by uploading one or more X-images, but also a Y-description ("label") of what the images contain (e.g., Y-"German shepherd dog" or Y-"pizza food").
Among the more than 14 million images are images of animals (dogs, birds, cats, frogs,...), devices (televisions, laptops, microwaves, pencils,...), foods (pizzas, hamburgers, fruits,...), etc., along with their human description Y.
The challenge of Imagenet is to design the best algorithm that, after a phase of machine learning with the millions of X images and their corresponding Y tags, will be able later in a later phase of prediction (or production) to recognize the content of a new image that you have never seen before (which you have not used in your learning phase). That is, given an X you've never seen before, predict and correctly (strictly, "with high probability", we'll talk about this on a second blog).
It is important for the reader to note at this point the different notation we use in this blog to refer to the sample data processed by the intelligent algorithm during its learning phase (X and Y, no bonuses“) of the notation (with bonuses) we use to refer to the data used in the production phase (X) and its corresponding predictions (Y).
This is what two-year-olds learn very well: if we show them a few pictures (X) and tell them that it is an elephant (Y=”elephant”), they will almost always be able to answer “it is an elephant” (Y) when we show them a new photo (X) of this animal, even though I have never seen this particular photo before.
The following diagram shows an outline of the learning phase of a smart algorithm for Imagenet.

In the case of the Imagenet challenge, X are the millions of images, and its millions of tags (made by humans) and the output of this learning phase is a code: the machine learned.
Once the learning phase is over and we have the code, we can use this code to predict the content (the Y' tag) of a new image (X´) that the machine has never seen before, as shown in the following figure.

In the case of the VGG19 machine (a deep convolutional neural network developed by the University of Oxford and trained with Imagenet images and tags), the resulting code after the learning phase contains 143,667,240 numbers (“parameters”), which at the beginning of the learning phase they were random and that after the learning phase they took very specific values.
During the learning phase, servers with high computing capacity, parallel processing, etc. were needed in addition to the 14 million Imagenet images with its fourteen million corresponding "human" tags for the algorithm to discover the values of these 140 million parameters in a reasonable time.
However, the learned machine (which we can put into production, integrating for example software image albums) occupies 561 MB on my hard drive , and I can run on the same laptop that I am writing this blog getting a response time of a second (the time that my laptop needs to make the prediction of the content Y´ of an image X´ that the Oxford group did not use to obtain the code of the algorithm).
The following figure shows the predictions (Y) made by VGG19 executed on my laptop for three images (taken from the Internet but not from Imagenet, therefore new to VGG19).
As we can see, VGG19 has correctly predicted the content of these images that I arbitrarily borrowed from the internet ("mobile", "Golden Retiever" and "cheeseburger").

Useful applications of machine learning
Instead of the Imagenet challenge we can imagine other similar challenges, with thousands / millions of digital inputs X with their human “tag” and associated: X the data of thousands of patient analytics (digitally stored) and Y the corresponding diagnoses made by doctors (also available digitally), or X tissue resonance images and Y the “cancer” or “non-cancer” label, or X thousands of digital recordings of conversations and Y the transcribed text (for example, the sessions of a parliament), or X thousands of texts in one language and Y their translations in other languages (for example, the sentences of the EU normative documents), or X the video recordings of a camera in a car and Y the driver's response to the situation (steering wheel direction, speed, accelerator, braking, lights, etc.), or X thousands of chess games and Y the result “wins” or “loses” , or X the digitized data of thousands of judicial summaries and Y the verdict ...
We can thus intuit how many of the newest ML applications that we have available today work, whose learning phase required in most cases large servers and capable data scientists, but now, in its production phase, sometimes work in an even small execution environment (such as smartphones) and that will give opportunities to the ICT industry (which do not have these data scientists), to integrate these learned machines into a multitude of solutions that increase every day.
When an assistant that we have seen in so many advertisements this Christmas (for example, Alexa) we say “lower the heating temperature by 5 degrees”, the assistant (basically a microphone and speaker connected to the internet) sends the phrase X' with our order to a server (from the assistant provider, for example Amazon) that with neural trained networks interprets our phrase and sends the command Y' to our domotic control of the heating (also connected to the Internet and having a service API capable of receiving and executing the command Y' to lower the temperature 5 degrees).
The business of the ICT companies that design the algorithms is and will fundamentally be in the sale of intelligent services or algorithms (monetization by cloud use, on-premises licensing, "free" in exchange for our data, etc.), while those ICTs that do not develop these algorithms can find their business niche in artificial intelligence by integrating these services and algorithms into new, high-value-added solutions for their clients.
In the next article Effectiveness and capacity beyond human intelligence we will talk about probability, black-boxes, brute force and give a formal definition of “Machine Learning”. Stay tuned.
Pablo Méndez Llatas, Project Manager