Hoy en día, Machine Learning aparece constantemente en la prensa especializada, y en ocasiones en la más general, con nuevas y sorprendentes aplicaciones, y todo el mundo “habla de ello”.
El objetivo de este post es que el lector no iniciado pueda adquirir una visión de alto nivel de este tema tan candente, incluyendo una definición formal de machine learning (que daremos al final del siguiente blog sobre el tema).

Inteligencia Artificial
Empecemos, para entenderlo, por la Inteligencia Artificial. Para la mayoría de nosotros, definir con precisión el término “inteligencia” puede resultar complicado. En general, todos tenemos nuestra propia “intuición” de qué es la inteligencia (aunque no podamos explicarlo con precisión); y existen definiciones formales dentro de distintas disciplinas :psicología, filosofía, neurociencias, informática...).
Si acudimos al diccionario de la RAE, nos encontraremos con el problema de que la definición de inteligencia depende de otros términos que, a su vez, es necesario definir y son también difíciles de explicar con precisión (“entender”, “razonar”, “resolver un problema”, …) y acabaremos en lo que en desarrollo de software se denominan dependencias cíclicas (un lío de definiciones que dependen de otras y entre sí, lejos de la simplicidad y la precisión).
La inteligencia artificial se puede definir informalmente como la capacidad de un programa informático de razonar y aprender como los humanos. Lector, “whatever it means, … “but you know what I mean”.
La visión (segmentar y reconocer objetos a partir de la fotosensibilidad de nuestras células de conos y bastones), aprender a hablar o escribir, traducir de un idioma a otro, conducir un coche, aprender a andar, pintar un cuadro o componer música, jugar al ajedrez, etc. son actividades humanas que normalmente se reconocen como “inteligentes”.
Aplicaciones que podemos llevar y ejecutar en nuestro smartphone (como traductores y asistentes), o en servidores en la nube como las recomendaciones de productos para comprar, bajar la temperatura del horno domóticamente utilizando la voz, el etiquetado automático del contenido de una fotografía, coches autónomos, robots que aprenden a andar y sortear obstáculos, etc. entran dentro, por tanto, de la definición intuitiva de aplicaciones (son ejecutados hoy en día por máquinas) y de inteligentes (ya que son tareas similares a las que en el párrafo anterior reconocíamos como inteligentes para los humanos).
No obstante, desde el aprendizaje que puede realizar un niño de tres años, capaz de distinguir en una foto un elefante de un león, o aprender a hablar correctamente y reconocer y ejecutar las órdenes que se le comunica (en el mejor de los casos, lo digo como abnegado padre), hasta el razonamiento que es necesario para definir una teoría cuántica de la gravedad (por poner un ejemplo de un problema actual que los humanos aún no hemos podido resolver tras décadas de intentarlo), hay un gran trecho.
Hoy en día, nos encontramos en el momento histórico en el que podemos diseñar programas informáticos con una muy alta capacidad de aprendizaje, pero aún muy lejos de atacar problemas “duros” por sí solos (… todo llegará).
El aprendizaje automático
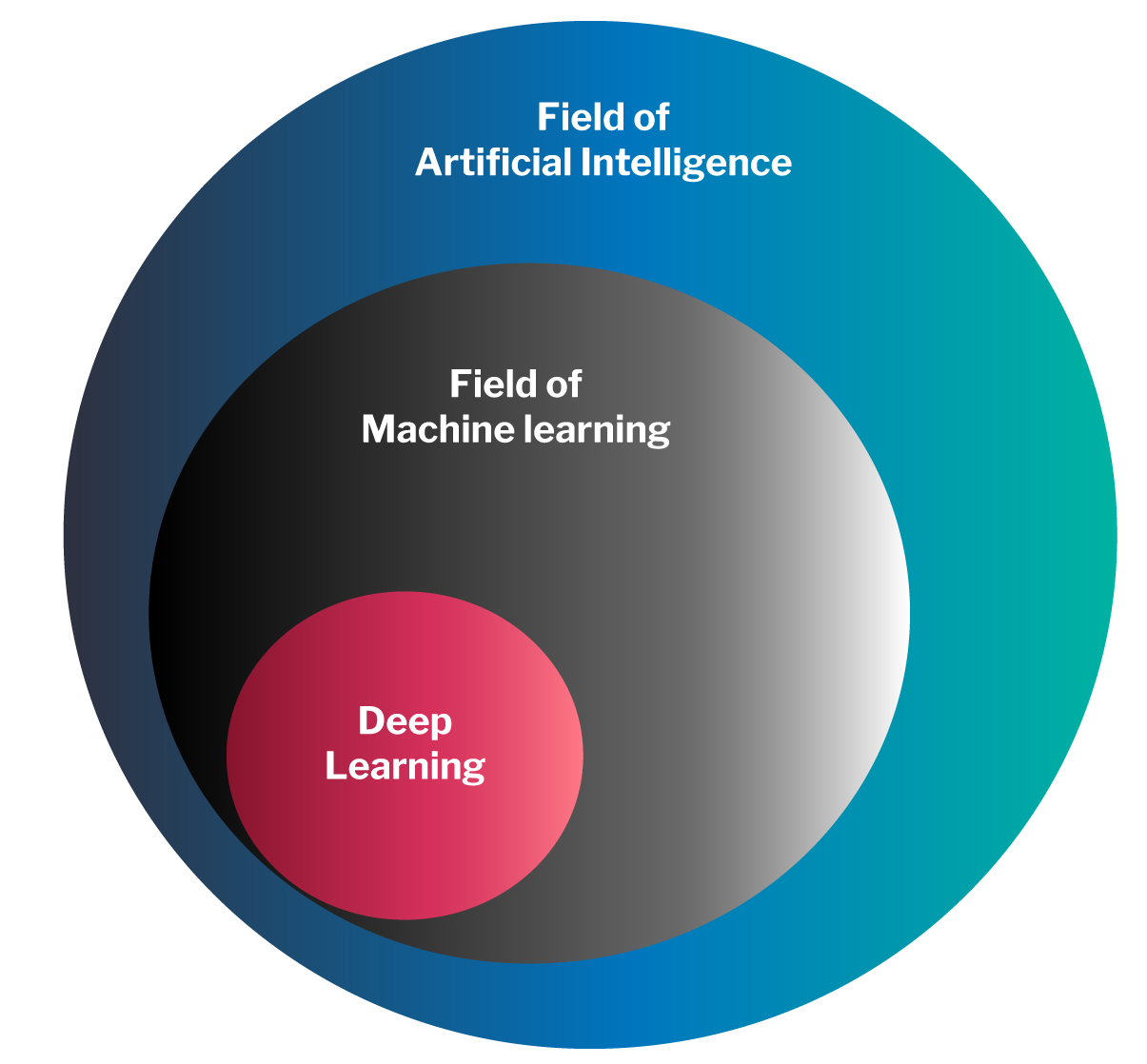
El aprendizaje automático (machine learning, en adelante ML) es una rama específica de la inteligencia artificial: ML es inteligencia artificial, pero no toda la inteligencia artificial es ML.
ML, no obstante, es la rama de la inteligencia artificial que está relacionada con la gran mayoría de las aplicaciones inteligentes que últimamente nos inundan y, muy destacadamente, el aprendizaje profundo (“deep learning””) basado en redes neuronales.
Peter Xenopoulos, Data Scientist y doctor en ciencias de la computación, reutilizando un Twitter de 2013 de Dan Ariely sobre big data, decía en 2017:
“ML es muy parecido al sexo entre adolescentes:
- Todos hablan de ello
- Solo algunos saben realmente cómo hacerlo
- Todos piensan que todos los demás lo hacen.
- Por tanto, todo el mundo afirma que lo están haciendo.”
Teniendo en cuenta que podemos considerar que, hoy en día, la industria TIC (en general) está en una edad joven, pero adulta en big data, podemos hacer un ejercicio de extrapolación y prever que la industria (en general) no dejará la adolescencia en ML al menos hasta el 2023.
“En general”, en mi anterior párrafo, significa “la mayoría”. Evidentemente, como Xenopoulus comenta, “algunos saben hacerlo”, pero generalmente son universidades y centros I+D, “blue chips” TIC con departamentos I+D+i (como Google, Amazon, IBM, …) y empresas muy innovadoras, generalmente start-ups, spin-offs de universidades/centros de investigación y que, en muchas ocasiones, son rápidamente absorbidas por los blue chips (a base de talonario) en cuanto tienen una aplicación de ML novedosa y con perspectivas de generar negocio.
Un ejemplo concreto de ML: El reto Imagenet
Hasta este punto todavía no hemos dado una definición formal de machine learning (ni lo haremos en este primer blog, habrá que esperar al segundo…). En mi opinión, la mejor forma de entender una definición formal se produce después de entender un ejemplo concreto y real.
El ejemplo escogido es el reto Imagenet. Imagenet es un repositorio que actualmente tiene 14.197.122 imágenes en color al que han contribuido personas de todo el mundo (liderados por centros de investigación como Stanford y Harvard). Estas personas han contribuido no solo subiendo una o varias imágenes X, también una descripción Y (“etiqueta”) de lo que contiene las imágenes (por ejemplo, Y=”perro de raza pastor alemán” o Y=”comida pizza”).
Entre los más de catorce millones de imágenes hay imágenes de animales (perros, pájaros, gatos, ranas, …), dispositivos (televisores, portátiles, microondas, lápices, …), alimentos (pizzas, hamburguesas, frutas, …), etc., junto con su descripción humana Y.
El reto de Imagenet es diseñar el mejor algoritmo que, tras una fase de aprendizaje automático con los millones de imágenes X y sus correspondientes etiquetas Y, sea capaz después en una fase posterior de predicción (o producción) de reconocer el contenido de una nueva imagen que nunca ha visto antes (que no ha utilizado en su fase de aprendizaje). Es decir, que dado un X´ que nunca ha visto antes, prediga Y´ correctamente (estrictamente, “con alta probabilidad”, de esto hablaremos en un segundo blog).
Es importante que el lector advierta en este punto la diferente notación que utilizamos en este blog para referirnos a los datos de ejemplo procesados por el algoritmo inteligente durante su fase de aprendizaje (X e Y, sin primas “´”) de la notación (con primas) que utilizamos para referirnos a los datos utilizados en la fase de producción (X´) y sus correspondientes predicciones (Y´).
Esto los niños de dos años los aprenden muy bien: si les enseñamos unas cuantas fotos (X) y les decimos que es un elefante (Y=”elefante”), casi siempre podrán responder “es un elefante” (Y´) cuando le enseñemos una nueva foto (X´) de este animal, aunque nunca haya visto antes esta foto en concreto.
En el siguiente diagrama mostramos un esquema de la fase de aprendizaje de un algoritmo inteligente para Imagenet.

En el caso del reto Imagenet, X son los millones de imágenes, Y sus millones de etiquetas (hechas por humanos) y el output de esta fase de aprendizaje es un código: la máquina aprendida.
Una vez finalizada la fase de aprendizaje y tenemos el código, podemos utilizar este código para predecir el contenido (la etiqueta Y’) de una nueva imagen (X´) que la máquina nunca ha visto antes, como mostramos en la siguiente figura.

En el caso de la máquina VGG19 (una red neuronal convolucional profunda desarrollada por la universidad de Oxford y entrenada con las imágenes y etiquetas de Imagenet), el código resultante tras la fase de aprendizaje contiene 143.667.240 números (“parámetros”), que al principio de la fase de aprendizaje eran aleatorios y que tras la fase de aprendizaje tomaron unos valores muy concretos.
Durante la fase de aprendizaje se necesitaron servidores con gran capacidad de cómputo, procesamiento paralelo, etc. además de los 14 millones de imágenes de Imagenet con sus catorce millones de correspondientes etiquetas “humanas” para que el algoritmo descubriera los valores de estos 140 millones de parámetros en un tiempo razonable.
No obstante, la máquina aprendida (que podemos poner en producción, integrándola por ejemplo en un software de álbumes de imágenes) ocupa 561 Mb en mi disco duro, y puedo ejecutarlo en el mismo portátil desde que escribo este blog obteniendo un tiempo de respuesta de un segundo (el tiempo que necesita mi portátil para realizar la predicción del contenido Y´ de una imagen X´ que no utilizó el grupo de Oxford para obtener el código del algoritmo).
En la siguiente figura, mostramos las predicciones (Y´) realizadas por VGG19 ejecutado en mi portátil para tres imágenes (tomadas de Internet pero no de Imagenet, por tanto, nuevas para VGG19).
Como podemos observar, VGG19 ha predicho correctamente el contenido de estas imágenes que arbitrariamente tomé prestado de internet (“móvil”, “Golden Retiever” y “hamburguesa de queso”).

Aplicaciones útiles del machine learning
En vez del reto Imagenet podemos imaginarnos otros retos similares, con miles/millones de inputs digitales X con su “etiqueta” humana Y asociada: X los datos de miles de analíticas de pacientes (almacenados digitalmente) e Y los correspondientes diagnósticos realizados por los doctores (también disponible digitalmente), o X imágenes de resonancias de tejidos e Y la etiqueta “cáncer” o “no cáncer”, o X miles de grabaciones digitales de conversaciones e Y el texto transcrito (por ejemplo, las sesiones de un parlamento), o X miles de textos en un idioma e Y sus traducciones en otros idiomas (por ejemplo, las frases de los documentos de normativa de la EU), o X las grabaciones en vídeo de una cámara en un coche e Y la respuesta del conductor ante la situación (dirección del volante, velocidad, acelerador, frenado, luces, etc.), o X miles de partidas de ajedrez e Y el resultado “gana” o “pierde”, o X los datos digitalizados de miles de sumarios judiciales e Y el veredicto, ... .
Podemos así intuir cómo funcionan muchas de las aplicaciones más novedosas de ML que ya tenemos hoy disponibles, cuya fase de aprendizaje requirió en la mayoría de las ocasiones de grandes servidores y de sesudos “científicos de datos”, pero que ahora, en su fase de producción, funcionan en ocasiones en un entorno de ejecución incluso pequeño (como smartphones) y que darán oportunidades a la industria TIC (que no dispone de estos científicos de datos), de integrar estas máquinas aprendidas en multitud de soluciones que cada día aumentan.
Cuando a un asistente de los que hemos visto en tantos anuncios estas navidades (por ejemplo, Alexa) le decimos “baja la temperatura de la calefacción 5 grados”, el asistente (básicamente un micrófono y un altavoz conectados a internet) manda la frase X´ con nuestra orden a un servidor (del proveedor del asistente, por ejemplo Amazon) que con redes neuronales entrenadas interpreta nuestra frase y envía la orden Y´ a nuestro control domótico de la calefacción (también conectado a Internet y que tiene una API de servicios capaz de recibir y ejecutar la orden Y´ de bajar la temperatura 5 grados).
El negocio de las empresas TIC que diseñan los algoritmos está y estará fundamentalmente en la venta de servicios o algoritmos inteligentes (monetización por uso en la nube, licencias on-premise, “free” a cambio de nuestros datos, etc.), mientras que el de las TIC que no desarrollan estos algoritmos podrá encontrar su nicho de negocio en inteligencia artificial con la integración de estos servicios y algoritmos en soluciones nuevas de alto valor añadido para sus clientes.
En el próximo artículo Efectividad y capacidad más allá de la inteligencia humana hablaremos de probabilidad, black-boxes, fuerza bruta y daremos una definición formal de “Machine Learning”. Estad muy atentos.
Pablo Méndez Llatas, Gerente de Proyectos