En este nuevo artículo, analizaremos la probabilidad de error, un ingrediente relacionado con el término performance o desempeño. También discutiremos sobre si realmente estamos hablando de inteligencia (whatever it means) o púramente de fuerza bruta (capacidad de cómputo).
En nuestro anterior post “pero ¿qué diablos es el machine learning?” hemos dado unas pinceladas de lo que significa inteligencia artificial, guiándonos por un ejemplo concreto de aplicación en visión artificial (una de las tareas reconocidas como inteligentes) de una red neuronal convolucional profunda (reto Imagenet).

No obstante, en dicho blog no llegamos a dar una definición formal de machine learning (en adelante, ML), ya que aún nos faltaba por analizar la probabilidad de error, un ingrediente relacionado con el término performance o desempeño (y parte integrante de la definición formal de ML, como veremos más adelante).
También, en este nuevo blog, discutiremos sobre si realmente estamos hablando de inteligencia (whatever it means) o púramente de fuerza bruta (capacidad de cómputo).
Probabilidad de error y black-boxes
En este punto del blog, tenemos claro que la rama ML de la inteligencia artificial se basa en el aprendizaje de una tarea (visión artificial, traducir, jugar al ajedrez, …) a partir de miles de datos (X,Y) de ejemplo (llamados también “muestras” u “observaciones”).
La ciencia que aprende y que extrae conclusiones de datos (muestras u observaciones) es la estadística, y la estadística es la ciencia de las probabilidades (o incertidumbres). Las conclusiones estadísticas no son deterministas: típicamente las conclusiones y predicciones tienen un grado de incertidumbre (grado de significación).
Los algoritmos ML, aprendiendo de datos y como no puede ser de otra manera, se basan “ab initio” en la estadística y, por tanto, el resultado de las tareas que ejecuta una máquina inteligente está sometido a las leyes de la estadística y, en particular, al error.
Dado que el error es también una característica muy humana, el error no invalida la característica “inteligente” de ML, pero sí la diferencia de los algoritmos más tradicionales y deterministas a los que estamos más acostumbrados en los procesos tradicionales de desarrollo de software (basada en pasos lógicos “if.. then… elese”) para los que, dado un conjunto de datos input concretos, el que diseña el “algoritmo tradicional” puede explicar con todo detalle el porqué del output.
Hoy en día, nadie puede explicar cómo VGG19 (la red convolucional profunda que utilizamos como ejemplo en nuestro anterior blog) es capaz de distinguir un Pastor Alemán de un Golden Retriever como un conjunto de pasos lógicos, de la misma manera que tampoco podemos explicar hoy en día cómo lo hacemos los humanos. Esta característica de algunos de los algoritmos ML, entre los que están las redes neuronales, se denomina “black-box” (caja negra: mi algoritmo hace buenas predicciones, pero no me preguntes el detalle de cómo lo hace).
La propiedad “black-box” de las redes neuronales tampoco invalida la propiedad “inteligente” de un algoritmo ML, ya que nuestro propio cerebro es hoy en día un enorme blackbox.
En la siguiente figura, volvemos a mostrar los resultados, y sus certidumbres (probabilidades de Y´), que nos devolvía el algoritmo inteligente VGG19 cuando le suministramos tres imágenes extraídas de internet (X´) en nuestro anterior blog:

Como vemos, hemos marcado para cada imagen X´ tres predicciones Y´ de la red neuronal convolucional profunda VGG19 con sus correspondientes tres probabilidades mayores. Las más probables son correctas, pero tenemos otras respuestas menos probables a considerar.
Ahora imaginemos que integro este algoritmo inteligente en una aplicación para etiquetar automáticamente imágenes de Instagram (por ejemplo), que no fueron etiquetadas por los propios usuarios que las subieron, y hago que la respuesta a poner en la etiqueta por este software inteligente es aquella para la que el algoritmo me da la mayor probabilidad de ser correcta (en el anterior ejemplo, “móvil”, “Golden Retriever” y “hamburguesa” respectivamente). En este caso, no pasaría nada irreparable si en vez de “Golden Retriever” el algoritmo me devolviese “Pastor Alemán” (quizás, con bastante probabilidad sea dicho, una queja de algún cliente).
No obstante, hay otras situaciones en la que estos errores no son aceptables. En 2015 salió en prensa la noticia de que el clasificador de imágenes de Google estaba (en ocasiones) etiquetando a personas de color como “gorilas” (ver imagen).
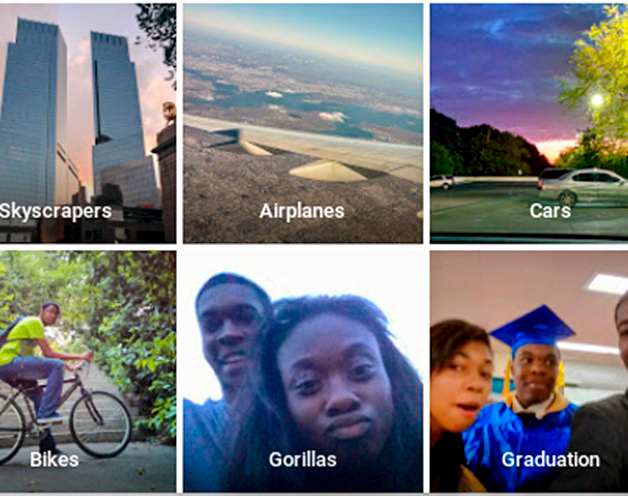
Por supuesto, Google desactivó inmediatamente su clasificador automático, pidió disculpas. Dos años después lo volvió a activar pero eliminando de las posibles respuestas “gorila”, con lo que el algoritmo nunca proporcionará Y´=”gorila” para ninguna imagen X´ y es imposible que se reproduzca el error (con el efecto colateral de que tampoco es capaz de etiquetar fotos de gorilas reales).
La probabilidad no nula de error (la indeterminación) en las predicciones es una propiedad inherente a ML (y, por cierto, a los humanos), y restringe su usabilidad en determinados problemas y/o momentos. En ejemplos como el anterior invalida la solución: nunca tendremos la certidumbre (100% de probabilidad) de que una red neuronal no etiquete a una persona como “gorila” (o como “pizza”), y algunos errores son imperdonables e invalidan el modelo (o, al menos, parte de él).
También, en prensa, vimos que el 18 de marzo de 2018 un coche autónomo de Uber había atropellado a una mujer en Arizona (con resultado de muerte). No obstante, todos los días mueren miles de peatones en todo el mundo atropellados por vehículos conducidos por humanos. ¿Cuál es la probabilidad de que un coche autónomo tenga un accidente comparado con la probabilidad de que un coche conducido por un humano tenga un accidente? En mi opinión, esta es la pregunta relevante para contestar antes de “demonizar” a los coches autónomos (como sucedió en marzo de 2018).
Me puedo perfectamente imaginar un futuro en el que nos sintamos más seguros si somos transportados por vehículos autónomos que por vehículos que conduzcamos nosotros mismos. También me puedo imaginar un futuro en el que nos sintamos más confortables con un diagnóstico y cirugía realizada por una máquina que por un humano. Lo hemos visto en las películas de ciencia ficción, pero hoy en día ya no es tanta ciencia ficción: Hal 9.000 en “2001: una odisea por el espacio”, en su faceta más amable, se llama hoy Alexa, Siri, Cortana, ... todos basados en redes neuronales profundas (inteligencia artificial).
¿Fuerza bruta o inteligencia?
En este punto del blog, el lector que no conociese ya los fundamentos de ML habrá incorporado otros jugadores al escenario (IoT, BigData, Industria o Sanidad 4.0, etc.) y entendido el por qué ahora (disponibilidad de (big)datos de todo tipo para el aprendizaje de todo tipo de tareas gracias a IoT, capacidad de almacenamiento y procesado masivo y paralelo de los mismos para un aprendizaje en un tiempo razonable gracias a BigData y la Ley de Moore, etc.). Pero ¿estamos hablando de inteligencia o de fuerza bruta?
A mis profesores de matemáticas no le hubiese impresionado mucho en los 80 que con 140 millones de parámetros ajustables (como tiene VGG19) fuese teóricamente viable resolver casi cualquier problema: “dame muchos parámetros ajustables y hago que mi gato baile tango”.
No obstante, estamos todavía lejos de tener la potencia de nuestro cerebro. Por ejemplo, una red neuronal artificial equivalente solo al córtex V1 de nuestro cerebro (solo uno de los cinco córtex visuales que se relacionan con nuestra capacidad de distinguir e identificar objetos mediante nuestro sentido de la vista) tendría del orden de 10 mil millones de “parámetros ajustables” (unos cuantos órdenes de magnitud superior a los parámetros ajustables de VGG19 y de cualquier algoritmo que exista hoy en día). Por tanto, si reconocemos que la visión humana es una actividad inteligente no podemos descartar que la fuerza bruta de nuestro cerebro sea uno de los ingredientes principales de nuestra inteligencia, así como tampoco decir que la máquina no es inteligente (solo es fuerza bruta).
Por otro lado, después de que los expertos en el juego Go analizasen sesudamente cómo una máquina (AlphaGo) venciese con técnicas de redes neuronales a Lee Sedol (campeón mundial) en 4 de 5 juegos, concluyeron que AlphaGo empleaba soluciones que los jugadores humanos (incluyendo a Lee Sedol) no habían considerado antes. Por tanto, la máquina inventó algo nuevo que no le había podido enseñar ningún humano y que fue determinante para vencer al campeón de estos.
Dejo al lector derivar sus propias conclusiones de si estamos o no hablando de inteligencia, en función de su propia definición intuitiva de este término.
Aprendizaje automático: definición formal
Finalizo este segundo blog con una definición más formal de ML, que espero ahora no nos suponga un obstáculo difícil de salvar.
Tom Mitchel define: “ML es el campo de la inteligencia artificial que se ocupa en construir programas informáticos que automáticamente mejoran con la experiencia. Un programa se dice que aprende de la experiencia E con respecto a algún tipo de tarea T y desempeño P si su desempeño en realizar tareas del tipo T, medido por P, mejora con la experiencia E”
Esta definición es aplicable a todo tipo de ML (aquí solo hemos puesto ejemplos de una tipología concreta de ML: aprendizaje “supervisado” y, fundamentalmente, redes neuronales).
Si ahora el lector que ha llegado a este punto del blog sustituye (para el ejemplo de referencia Imagenet que hemos venido utilizando en estos blogs): E por los pares (X,Y) de imágenes y etiquetas “humanas”, T por “tarea de reconocer el contenido de una nueva imagen X´” y P por “probabilidad de error en la predicción Y´ obtenida”, acabará la lectura de este blog entendiendo una de las definiciones formales más usadas en la literatura de Machine Learning.
Su aplicación a otras tareas T (“realizar un diagnóstico”, “traducir un texto”, …), otros datos de partida para el aprendizaje (X,Y) (“analíticas y diagnósticos”, “texto original y texto traducido”…) y otras mediciones de desempeño P (“probabilidad de diagnósticos Y´ incorrectos”, “probabilidad de frases Y´ mal traducidas”, …) son inmediatas.
Pablo Méndez Llatas, Gerente de Proyectos