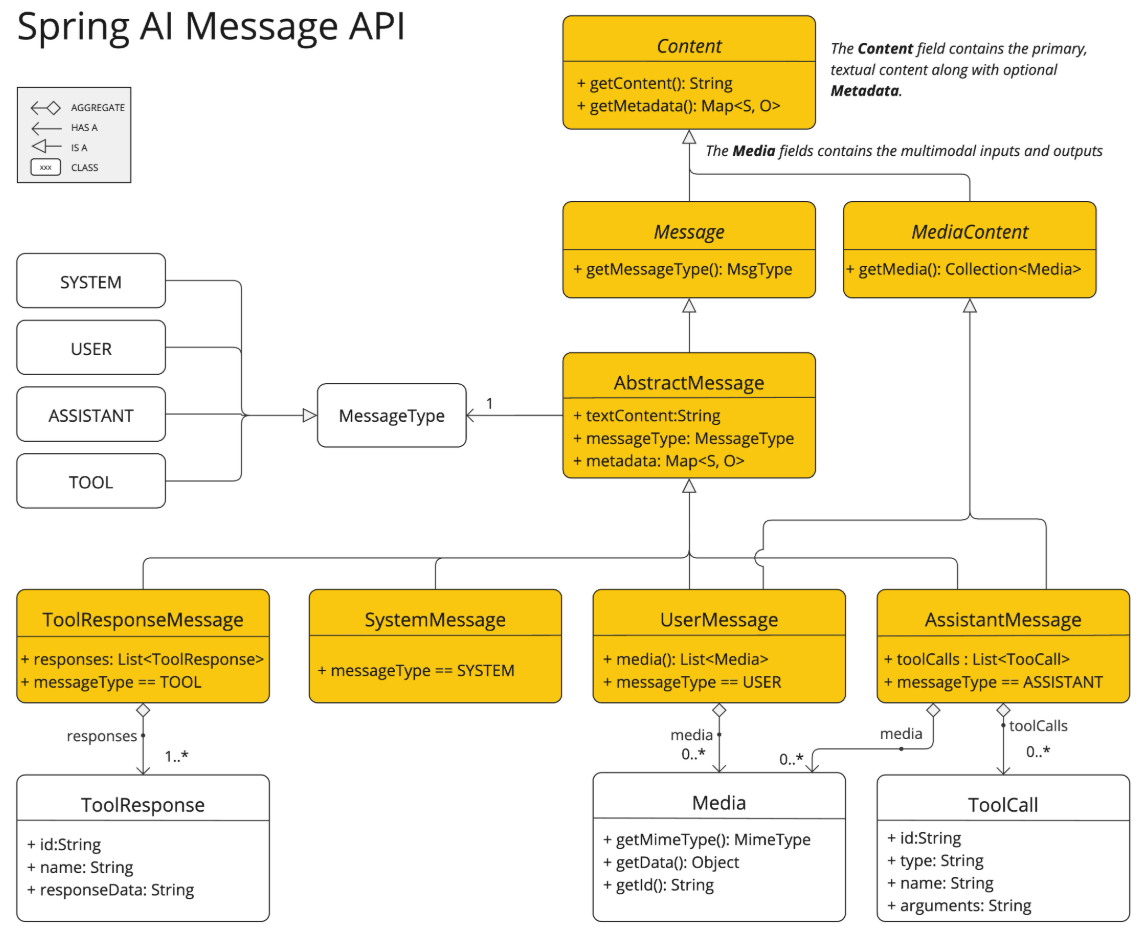
Spring AI
Spring AI es una librería de Spring Boot que permite integrar modelos de inteligencia artificial en nuestras aplicaciones de forma sencilla, facilitando la conexión con distintos modelos de inteligencia artificial, ya sea de la nube o en local.
¿Qué es?
El propósito de Spring AI es facilitar a los desarrolladores de Java el uso de IA generativa sin tener que manejar directamente las APIs de los diferentes modelos de cada proveedor, ya que cada una puede tener un uso y configuración diferente. Esto permite ahorrar tiempo y reutilizar código, pudiendo cambiar de motor de IA sin tener que reescribir todo el código.
Spring AI no es un modelo de IA por si mismo, no ejecuta modelos ni almacena datos, sino que se encarga de enviar las solicitudes a los proveedores de IA y recibir las respuestas listas en forma de objeto para usar en nuestra aplicación.
¿Cómo funciona?
Para esta explicación se usará un servidor local con ollama y el modelo llama3.1, aun así el funcionamiento del framework es prácticamente el mismo independientemente de nuestro proveedor y modelo elegido.
1. Dependencia en el proyecto:
Se deben usar las dependencias adecuadas dependiendo del proveedor concreto que se desee usar, además de la configuración para que la aplicación pueda arrancar o se puedan usar los clientes.
Dependencia para usar Ollama como servidor:

2. Configuración:
La configuración se hace a través de los archivos de propiedades como el application.yml o el application.properties.
Se hace bajo la propiedad base de spring.ai. …
Justo dentro de eso se pone el proveedor y el modelo que se desea usar y además las credenciales o claves necesarias para poder usarlo (tokens, api keys, …)
Entre los proveedores se encuentran OpenAI, Anthropic, Google/Vertex AI, Azure OpenAI o Ollama/ LocalAI.
Un ejemplo de configuración básica sería:
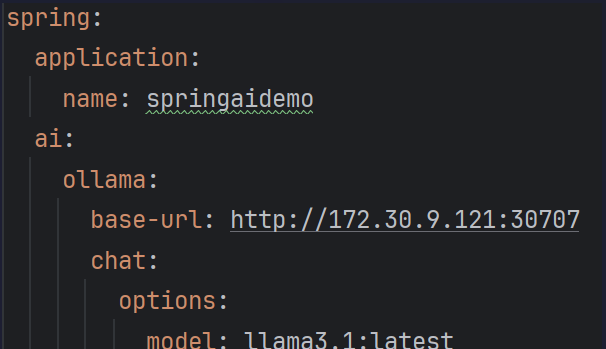
Se pueden añadir más opciones dentro de esa configuración, parámetros como max-tokens, stop-sequences, temperature, etc.
Y además también se pueden añadir varios proveedores en paralelo.
spring:
ai:
openai:
api-key: $|LF|OPENAI_API_KEY|RF|
chat:
options:
model: gpt-4o-mini
ollama:
host: http://localhost:11434
models:
llama2:
model: llama-2-7b
Mas adelante se verán otro tipo de configuraciones, de RAG, de bases de datos, y otras configuraciones avanzadas.
Una vez configurado el proveedor, modelo, credenciales, etc, se puede empezar con el ejemplo básico de funcionamiento.
3. Elementos básicos:
En este punto se tratará el funcionamiento básico de la librería, tratando siempre la forma de chat como la forma principal, aunque se explicarán también otras posibilidades de generación.
- ChatModel es la interfaz principal con la que se trabajará en este ejemplo, de ella parten todas las implementaciones de chat básicos, por ejemplo OllamaChatModel, OpenAiChatModel, BedrockChatModel, etc.
ChatModel es la forma de interactuar con los diferentes LLM en forma de chat. Es independiente al modelo de ia que se use ya que se usan los mismos métodos de llamada, prompt, respuesta, opciones, etc. Dependiendo de la implementación elegida, el framework actuará de una forma u otra. El principal método que tiene la interfaz ChatModel es el método call(), que recibe un objeto de tipo Prompt y devuelve uno de tipo ChatResponse.
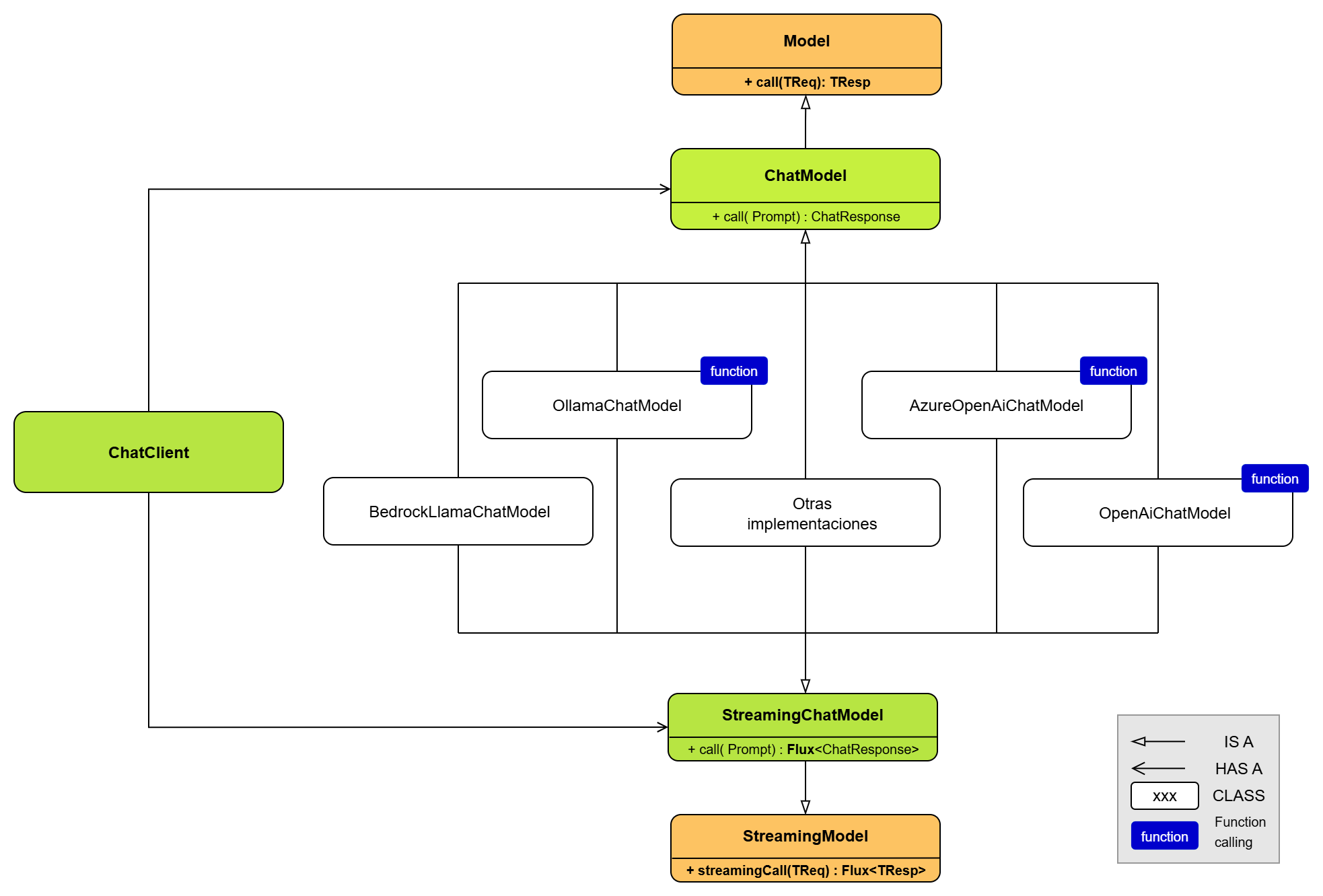

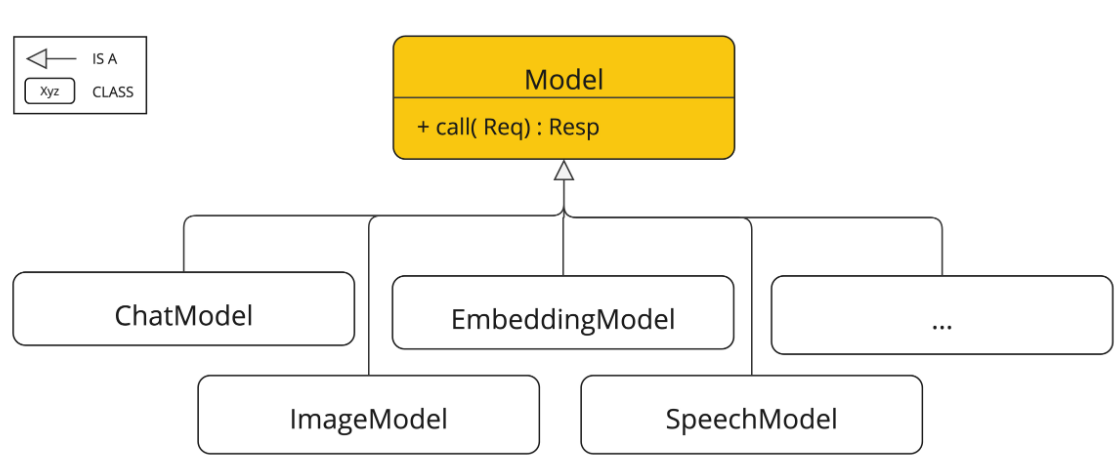
Como se puede apreciar, esta interfaz a su vez extiende la clase Model, que es la clase base de donde nacen todos los modelos como por ejemplo la interfaz ImageModel (para generar imágenes), DocumentEmbeddingModel (para generar embeddings vectoriales a partir de documentos), o AudioTranscriptionModel (para pasar de audio a texto). Estas interfaces solo se pueden usar si el modelo soporta ese tipo de generaciones, es decir si un modelo está preparado para generar texto no se le puede pedir que genere imágenes, por ejemplo.
La implementación de ChatModel que se usa en este ejemplo es la de OllamaChatModel, ya que en este ejemplo se esta usando ollama. Gracias a usar la dependencia de ‘spring-ai-ollama-spring-boot-starter’ del apartado 1 se crea un bean automáticamente que levanta un objeto de la clase OllamaChatModel y no se tiene que instanciar a mano. (La clase que levanta el bean inicial es OllamaAutoConfiguration).
El principal uso de OllamaChatModel es el de su método call() como se ha mencionado anteriormente, es el método que se usa para llamar a la api y además dispone de otros métodos importantes como getDefaultOptions() o withDefaultOptions() por si se desea tener una propia instancia de OllamaChatModel.

También es importante explicar la interfaz ChatClient, es una interfaz de más alto nivel pensada para facilitar la interacción con ChatModel. Se puede construir mediante builders o mediante otro ChatModel, y facilita la interacción con el modelo. ChatClient no sustituye a ChatModel, sino que lo usa por debajo para ofrecerte una interacción más sencilla, finalmente acaba delegando en el mismo método call que tiene ChatModel. A pesar de que parezca más sencillo de usar, en este ejemplo se explica y usa ChatModel porque se puede tener un mayor control ya que se trabaja a un nivel más detallado, prompts, roles de usuario (usuario, asistente, sistema), historial de conversación, opciones del modelo, etc.
Como se ha mencionado antes, otra clase importante es la clase Prompt, que es el tipo que recibe de parámetro el método call del ChatModel usado. El tipo prompt representa la entrada que se le da a un modelo de lenguaje. Es el contenedor que define qué se quiere que el modelo haga y cómo debe interpretarlo. Sus partes son:
- Contenido principal: Texto que quieres que el modelo procese.
- Mensajes: Lista de objetos Message, cada uno con un rol (user, assistant, system) y un contenido, permite construir conversaciones completas.
- Opciones adicionales: Parámetros como temperatura, máximos tokens, top-k, etc. (dependiendo de la implementación concreta del modelo).
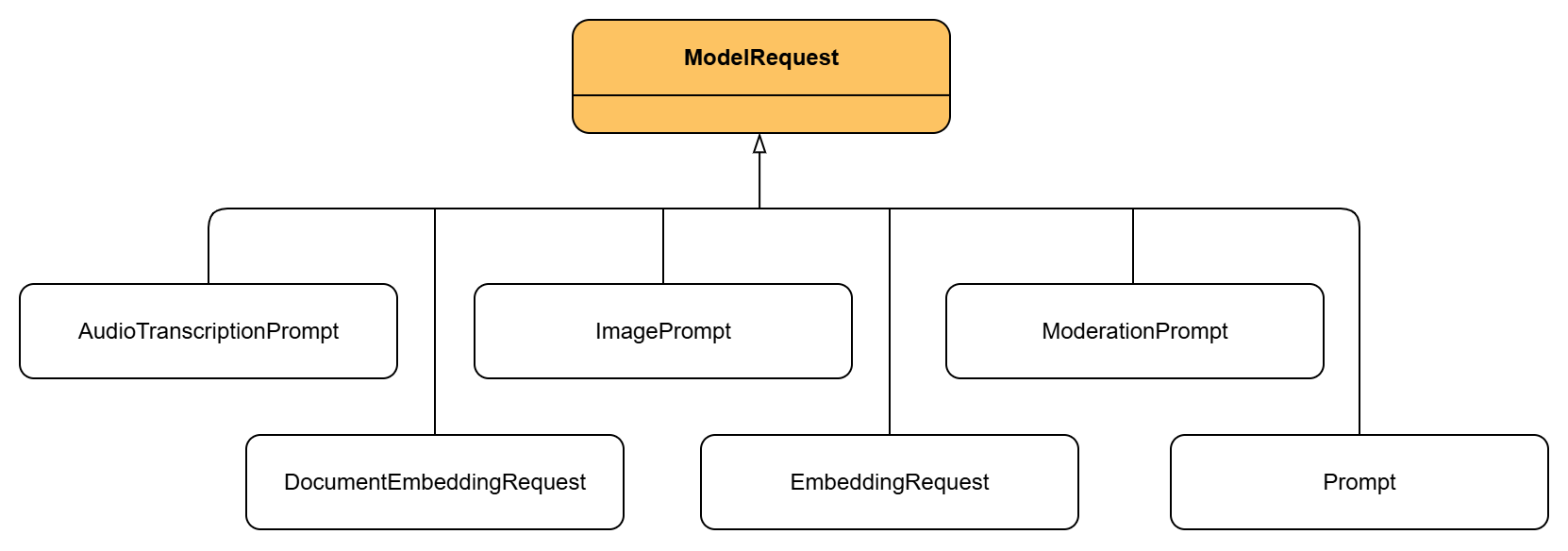
Esta clase es una implementación de ModelRequest, que de forma parecida a Model es la interfaz base de donde parten el resto de implementaciones de prompts, como por ejemplo ImagePrompt o AudioTranscriptionPrompt.
ChatResponse es la clase que representa la respuesta que devuelve un modelo de chat tras procesar un prompt. Es el tipo devuelto por la función call de ChatModel, además del texto generado contiene información adicional sobre la respuesta. Es útil porque estandariza la salida de un ChatModel sea cual sea la implementación elegida. Sus partes son:
- Result: de tipo Generation, es el bloque principal de la respuesta. Contiene el contenido generado y metadatos.
- Output: de tipo AssistantMessage, el Output almacena el texto real generado por el modelo.
- Messages: Lista de objetos de tipo Message que tienen el historial de la conversacion. Cada Message tiene un rol y un contenido.
Para finalizar, es importante explicar la clase Generation, que representa el resultado concreto de un chat dentro de un ChatResponse y implementa la interfaz ModelResult. Al igual que Model o ModelRequest, ModelResult define un contrato genérico para los resultados de cualquier modelo. Además de Generation, existen otras implementaciones de ModelResult adaptadas a distintos tipos de modelos, como ImageGeneration para generación de imágenes o AudioTranscription para transcripciones de audio.
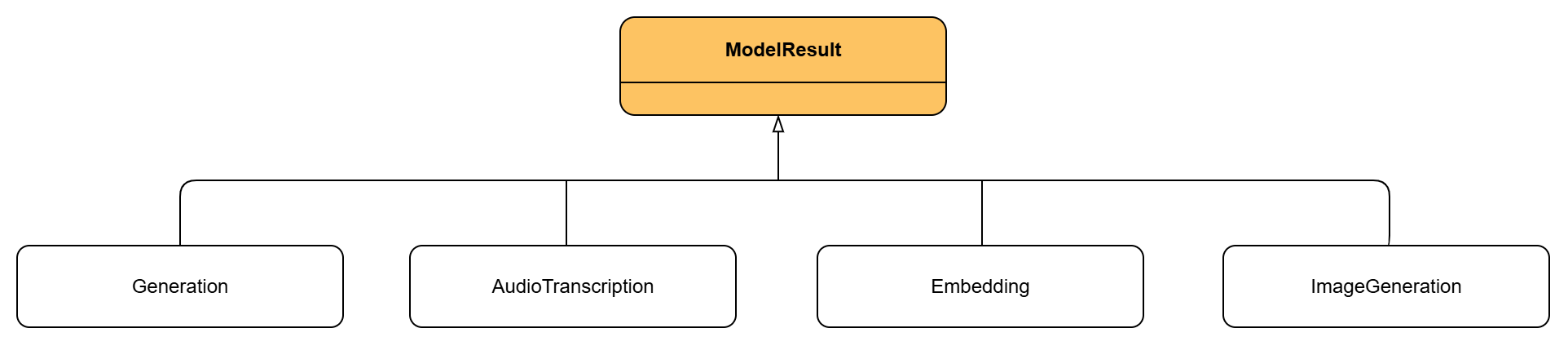
Por otro lado ModelResponse es la interfaz que representa la respuesta genérica de cualquier modelo en Spring AI. Envuelve uno o varios ModelResult junto con posibles metadatos, garantizando una estructura uniforme. Gracias a ella, respuestas de distintos modelos (texto, imágenes, embeddings, audio) pueden manejarse de forma consistente bajo un mismo contrato.

4. Flujo básico de trabajo:
Como ya se ha explicado los componentes principales, ahora se explicarán las diferentes funcionalidades del framework. Para simplificar el código y facilitar la comprensión, todos los textos se han puesto escritos en código pero esto en una aplicación real podría ser una entrada de usuario, o un texto que venga de otra función o cualquier otra forma de obtenerlo, no tiene por que ir escrito siempre en el código.
- Uso principal de los componentes básicos.
- Petición y respuesta simple:
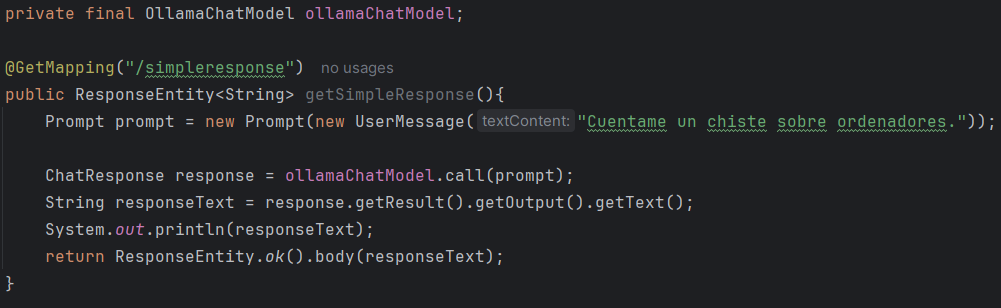
Como se puede apreciar en la imagen, se hace uso del ChatModel de tipo OllamaChatModel y de su método principal call. Ese método recibe como parámetro un objeto de tipo Prompt creado justo arriba, que a su vez recibe un objeto de tipo Message, en este caso un UserMessage. (Para simplificar y como el constructor puede recibir Strings, no será común ver en los ejemplos que se usen objetos de tipo Message, aunque es altamente recomendado usarlos para llevar un control completo de la conversacion). La función call devuelve un objeto de tipo ChatResponse y finalmente se extrae el texto de la respuesta para devolverlo.
- Prompt con parámetros:
También se pueden pasar argumentos al prompt usando un objeto de tipo PromptTemplate de la siguiente manera:

Se crea un mapa con las variables que se le quieren pasar y se usa la función create de PromptTemplate que ya devuelve el tipo Prompt deseado por la función call.
- Pasar contexto previo al prompt:

Como se ha explicado anteriormente, hay varios tipos de Message y al constructor del prompt se le puede pasar una lista de mensajes. Esta forma es la mas sencilla de pasarle contexto, aunque posteriormente se explicarán otras formas mas eficaces de enriquecer un prompt.
- Obtener respuestas estructuradas.
Como se ha explicado anteriormente, una de las ventajas de usar este framework es que se puede mapear la respuesta al tipo deseado, tipos como List, o Map, o un tipo personalizado como se vera en los siguientes ejemplos. Se puede convertir la respuesta si se usan objetos de tipo Converter.
Converter es la interfaz principal de la que parten los conversores. Se usarán las implementaciones, MapOutputConverter (para convertir a mapa), ListOutputConverter (para convertir a lista) y BeanOutputConverter (para convertir a un objeto del tipo que sea).
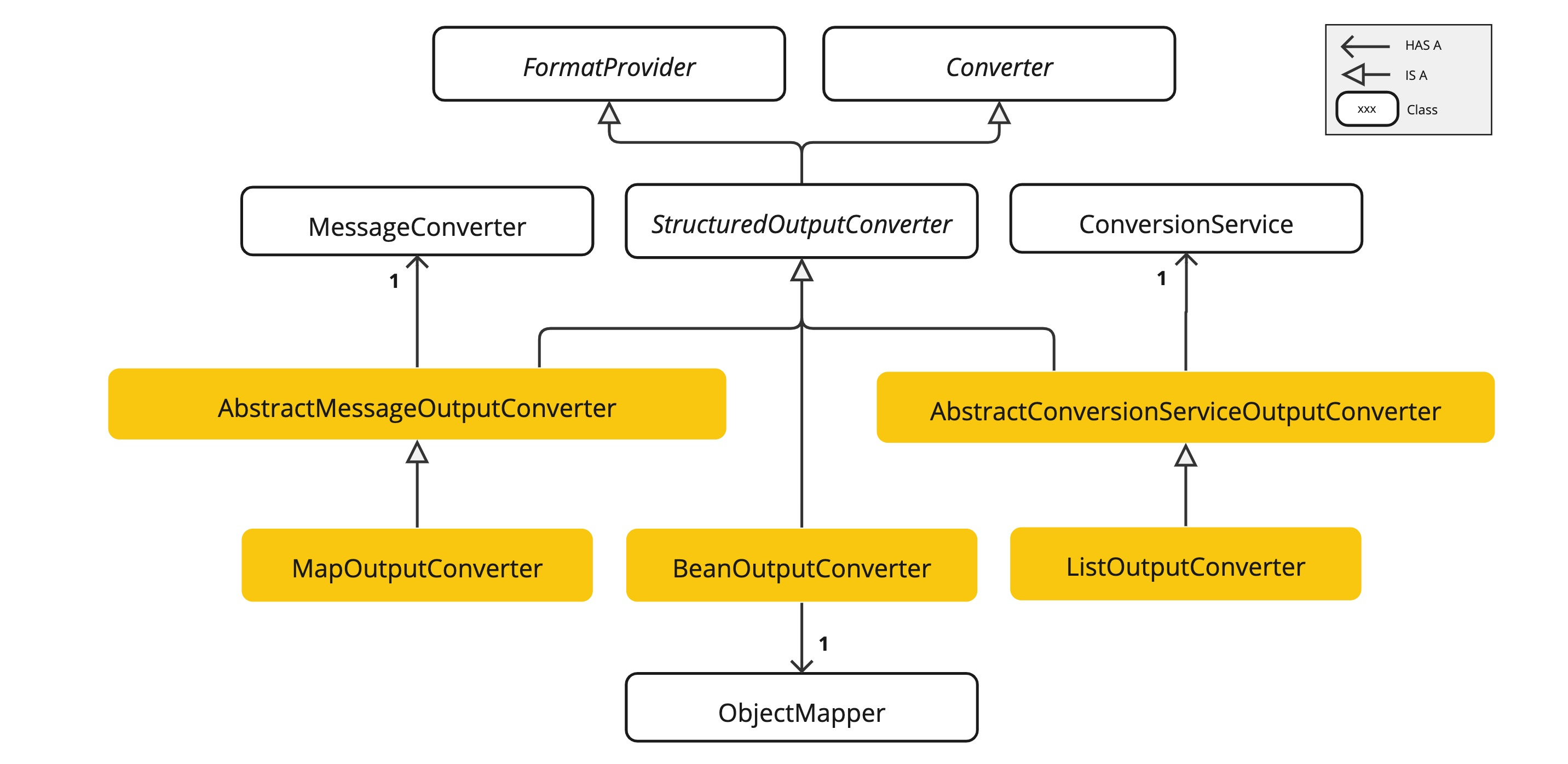
- Uso de MapOutputConverter:
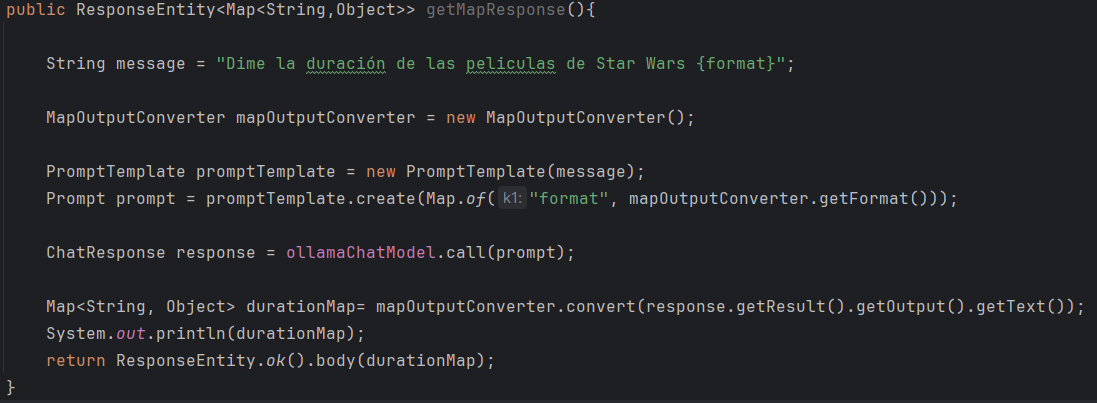
Como se puede ver el funcionamiento es parecido a cuando se usan parámetros en el prompt. Se hace uso de la función getFormat() de MapOutputConverter para pasarle el formato deseado al prompt, y finalmente se usa el método convert() para obtener de la respuesta el tipo de objeto deseado.
- Uso de ListOutputConverter:
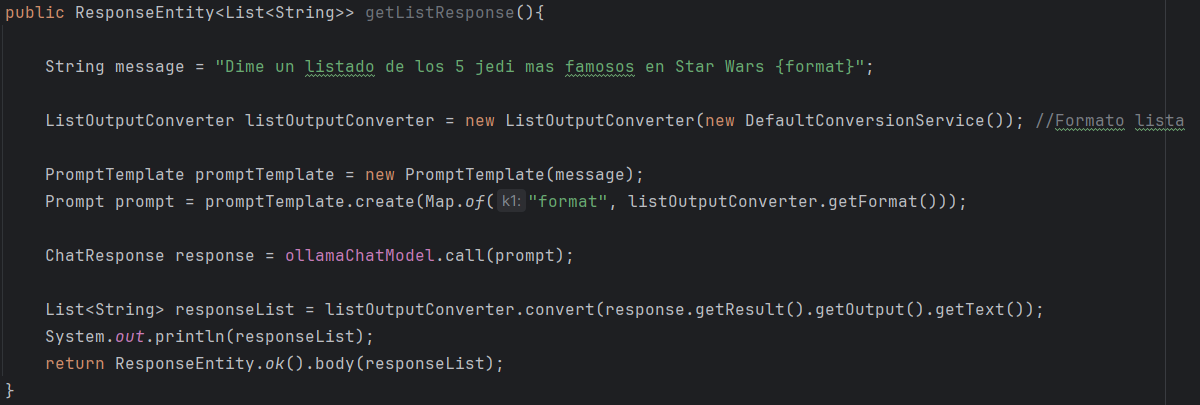
El funcionamiento es el mismo, solo que el tipo de Converter ha cambiado, como se esta convirtiendo a lista se usa ListOutputConverter.
• Uso de BeanOutputConverter:
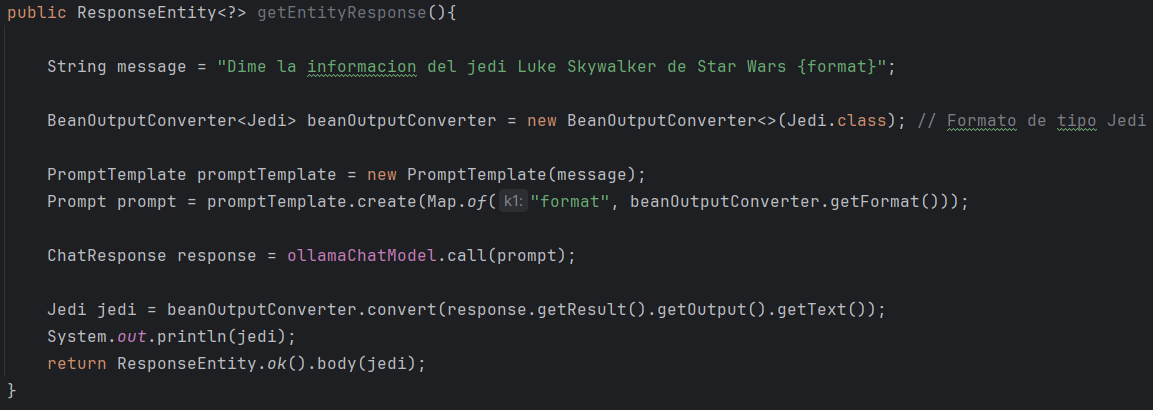
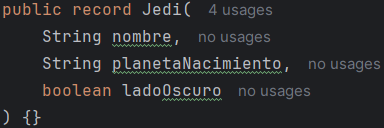
Esta es la forma mas útil de conversión ya que se puede convertir la respuesta a cualquier tipo de objeto necesario para la aplicación, en este caso hay una clase Jedi a la que se desea convertir. Simplemente se le pasa como tipo Jedi al BeanOutputConverter y se usan los métodos al igual que en las anteriores formas de conversión.
- Enriquecimiento del prompt
Un prompt es necesario que sea enriquecido cuando no tiene la información necesaria para contestar a la pregunta, porque el modelo no tiene esa información. Normalmente es porque es información muy reciente o con fecha posterior a los últimos datos con los que el modelo ha sido entrenado.
En este apartado se tratarán las tres formas de enriquecer un prompt. La primera es cuando se meten datos a mano como contexto en el prompt, la segunda es cuando usas un RAG con una base de conocimiento externa, y la tercera forma es cuando usas la llamada a métodos o herramientas que proporcionen información adicional.
- Proporcionar contexto al prompt:

Concepto sencillo, ya se ha tratado anteriormente, en este caso, consiste en añadir un parámetro al prompt con poco contenido. Bien sea un texto a mano, un fichero, etc. El hecho de que sea pequeño el contenido es para que la petición no tenga muchos tokens, ya que esto haría mucho mas caras las peticiones a los modelos que funcionan con tokens. Si se tiene un modelo en local como en este ejemplo, el hecho de añadir mas contenido a la pregunta solo ralentizara la respuesta por parte del modelo.
- Usando un RAG (Retrieval-Augmented Generation)
Primero hay que entender en que consiste esta técnica.
Esta es quizás la forma mas común de enriquecer un prompt, consiste en buscar información relevante en una colección o base de datos de embeddings e inyectar esa información al prompt para que la respuesta se fundamente en estos datos externos y no solo en lo que el modelo sabe.
Un embedding es una representación matemática de un texto, una imagen o un audio en forma de vector de números. Estos vectores se generan de tal manera que expresan relaciones semánticas: frases con significados parecidos tienen vectores cercanos en el espacio vectorial. Por ejemplo, “coche” y “automóvil” estarán más próximos que “coche” y “jirafa”.
Cuando un usuario hace una pregunta (prompt), esa pregunta también se convierte en un vector embedding. Una vez vectorizado, el sistema puede compararlo con los embeddings almacenados en la base de datos para encontrar aquellos más cercanos.
Para guardar y buscar embeddings se utilizan bases de datos vectoriales. En este ejemplo se han usado usado estos tipos:
- En memoria: soluciones simples donde los embeddings se almacenan en estructuras en memoria (útil para pruebas o volúmenes pequeños).
- Bases de datos extendidas: algunas bases tradicionales como PostgreSQL ofrecen extensiones (ej. pgvector) que permiten manejar embeddings.
Para simplificar todo el trabajo, está la interfaz VectorStore, que define funciones como add() para almacenar embeddings, similaritySearch() para buscar similares o delete() para borrar. Permite cambiar el proveedor de base de datos (memoria, PostgreSQL, etc) sin necesidad de alterar el código. Las implementaciones que se han usado en este ejemplo son SimpleVectorStore y PgVectorStore aunque hay algunos mas. (Se necesita dependencia adecuada en el pom para usar este tipo de base de datos).
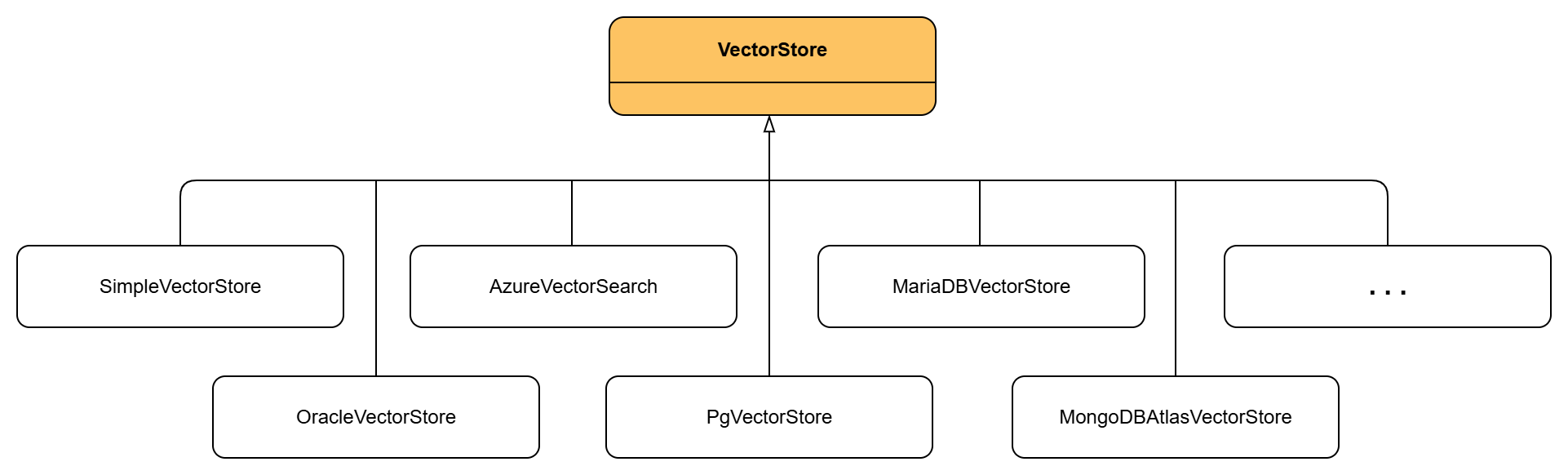
Dicho esto, esta es la primera forma con SimpleVectorStore. Importante tener descargado el modelo mxbai-embed-large.
1. Creación del fichero vectorstore.json que sera el que contenga los datos:
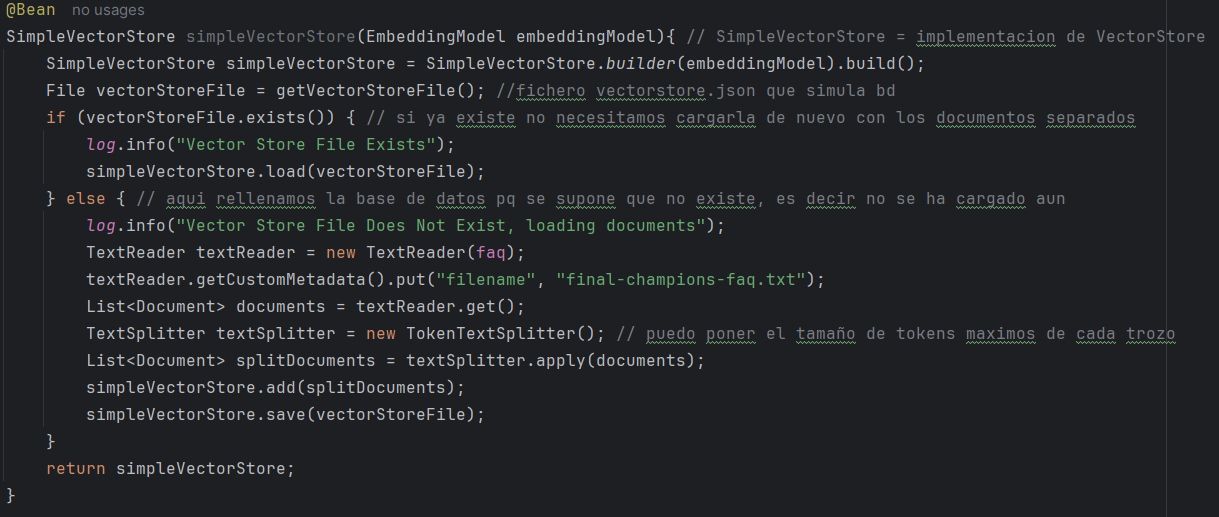
En este caso se crea el bean a mano en una clase de configuración, esto crea un objeto de tipo SimpleVectorStore con la base de datos. Si no existe, como es el caso de la primera vez, este código crea la base de datos, y si existe simplemente la devuelve. Este proceso puede tardar unos minutos, depende por supuesto del tamaño del fichero que uses y de la potencia del servidor ya que este contenido vectorial lo genera el modelo mxbai-embed-large que se ha mencionado anteriormente (en este caso y para el ejemplo es un fichero de texto con preguntas y respuestas sobre la final de la Champions League de fútbol)
2. Uso de esta base de datos como RAG:
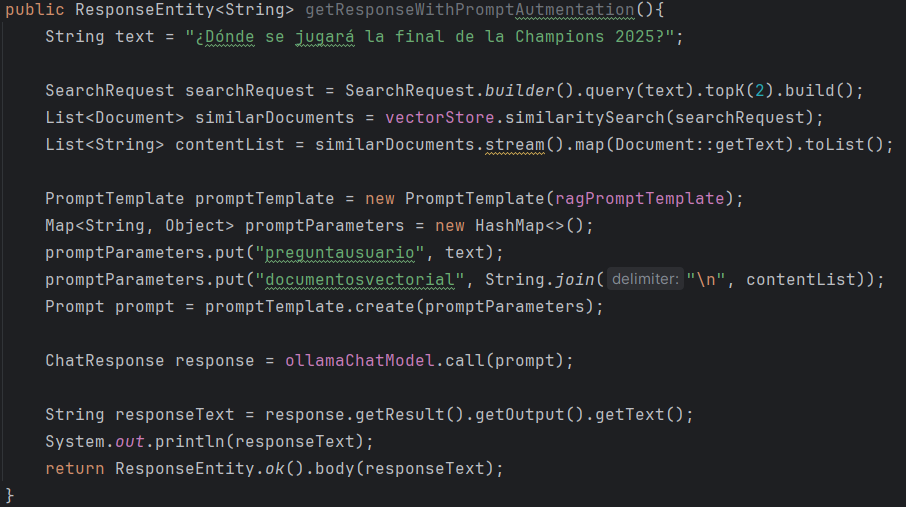
En este método se aplica el patrón RAG: primero, la pregunta del usuario se convierte en una consulta (SearchRequest) que busca en la base vectorial los documentos más similares mediante vectorStore.similaritySearch. Esos documentos recuperados se transforman en texto y se integran en una plantilla de prompt (PromptTemplate). Finalmente, el prompt resultante combina la pregunta original del usuario con la información contextual extraída de los embeddings, de modo que el modelo pueda generar una respuesta fundamentada en datos relevantes y no solo en su conocimiento entrenado. Por ultimo decir que la variable vectorStore, es de tipo SimpleVectorStore a pesar de que no aparezca en la imagen.
La segunda forma de hacerlo con PGVectorStore:
1. Creación de la base de datos:
Se proporcionan instrucciones al final del documento sobre cómo ejecutar el contenedor que tiene la base de datos, este contenedor ejecutará un script que crea el contenido básico, unas extensiones necesarias, la tabla y un índice.
2. Uso de esta base de datos como RAG:


El funcionamiento del método es el mismo, por eso no se adjunta imagen del método completo, la única diferencia es que la variable vectorStore ahora es de tipo PGVectorStore, ya que se esta usando otro tipo de base de datos, pero como se aprecia en la imagen anterior, la forma de usar los métodos es exactamente la misma.
• Llamada a métodos
Llamar a métodos es una forma de enriquecer un prompt porque permite incorporar información adicional al contexto que recibe el modelo. En lugar de limitarse solo a la instrucción del usuario, se pueden añadir datos externos (como búsquedas en base de datos, cálculos, consultas a servicios de terceros, etc). De este modo, el modelo responde no solo con su conocimiento entrenado, sino también con información más precisa y actualizada.
Para esta técnica, conocida como tool calling, y anteriormente como function calling (deprecado), el framework ofrece la anotación @Tool con la que se puede marcar las funciones especificas que se quiere que el modelo use antes de devolver la respuesta. El funcionamiento sigue el siguiente flujo de la imagen.
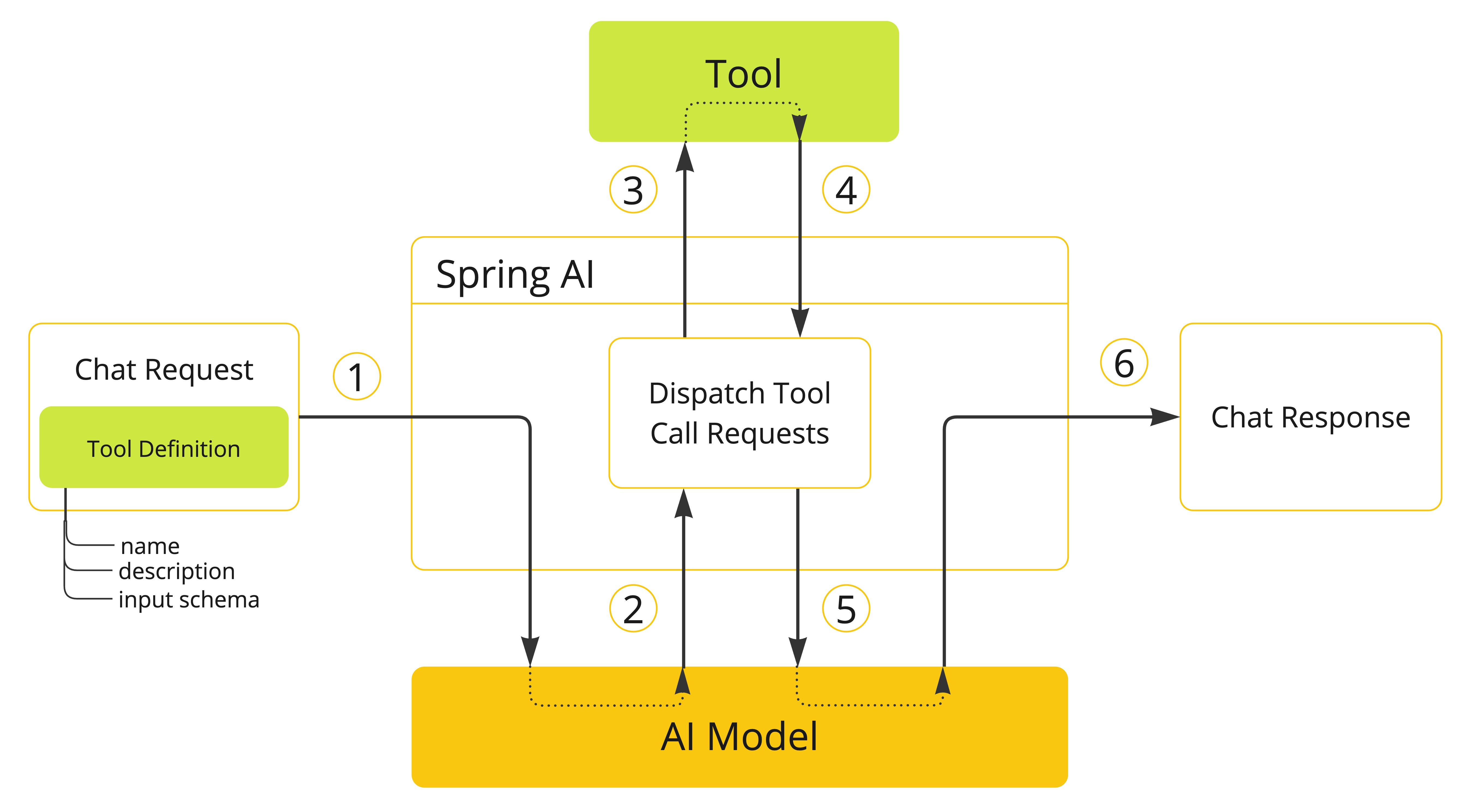
Como se ha mencionado anteriormente la anotación principal es @Tool, y sirve para marcar un método como una herramienta disponible para el modelo. Permite añadir nombre, descripción y metadatos dentro de la anotación, esto es importante por que es lo que el modelo usará para decidir que función usa, entonces tiene que estar bien definido y con una responsabilidad clara. También existe otra anotación @ToolParam, se usa en los parámetros del método para describirlos (nombre, descripción, etc.), de modo que el modelo sepa cómo invocar la herramienta correctamente.
Ejemplos:
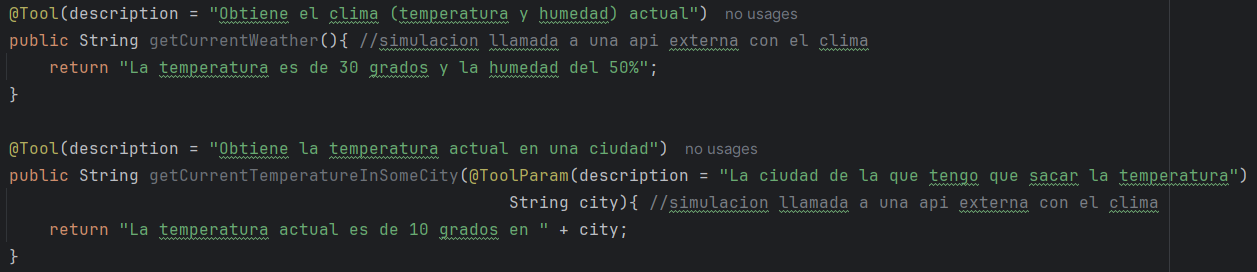
Y ahora el uso de estos métodos, hay dos formas de usar, la primera con ChatClient y tools directamente, es la mas sencilla de utilizar, y la segunda es con ChatModel y ToolCallbacks.
- Primera forma con ChatClient y tools:
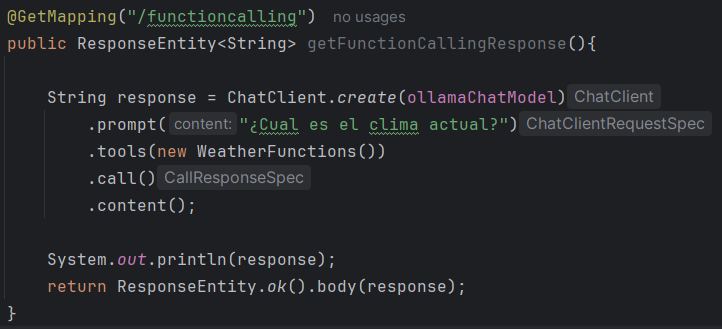
Como se puede apreciar, en la función tools es donde se le pasa la clase donde tienen las funciones y gracias a la descripción que se les ha puesto .
- Segunda forma con ChatModel y ToolCallbacks
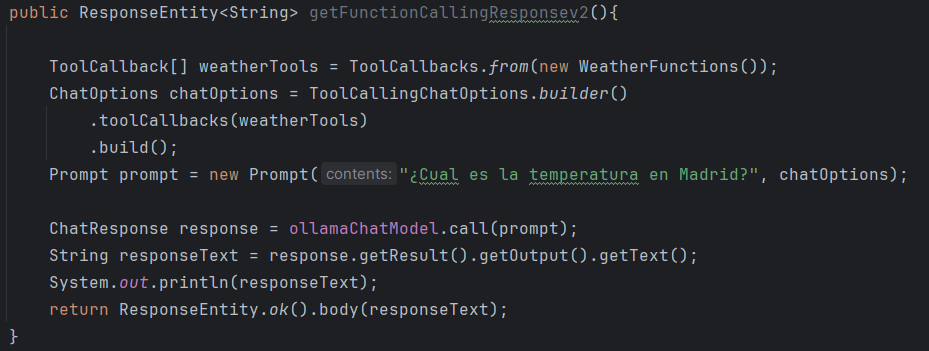
En este fragmento se registran las herramientas que el modelo puede invocar. WeatherFunctions se convierte en ToolCallback, definiendo métodos disponibles para el modelo. Esos callbacks se añaden a las opciones del chat (ChatOptions), creando un contexto con las herramientas activas. Al construir el Prompt, se combina la pregunta del usuario con estas opciones, permitiendo al modelo decidir si llama a una herramienta para generar la respuesta.
Conclusión
Spring AI facilita enormemente el desarrollo de aplicaciones de inteligencia artificial al proporcionar una capa de unificación y consistencia que permite trabajar con distintos modelos sin depender de un proveedor concreto. Ofrece flexibilidad y control, de modo que las aplicaciones pueden generar respuestas precisas y adaptadas a cada contexto. Aunque en los ejemplos se ha trabajado principalmente con texto, el framework es igualmente útil para imágenes, audio y otros tipos de datos, ampliando mucho las posibilidades de uso. Además, permite integrar acciones externas y combinar información de distintas fuentes, mejorando la calidad y relevancia de las respuestas. En conjunto, Spring AI aporta robustez y facilidad de mantenimiento, convirtiéndose en una herramienta muy potente para construir soluciones de IA modernas y completas dentro del ecosistema de Spring Boot.
Para las personas interesadas en probar el código, las instrucciones de instalar ollama y la base de datos están en el README.md en la carpeta raíz del proyecto.

Francisco Fernández
Técnico de Software
Altia