Clickhouse
En esta ocasión, nuestros Hunters nos hablan de ClickHouse, una base de datos OLAP columnar, distribuida y open source que está transformando la forma en la que trabajamos con grandes volúmenes de datos.
ClickHouse
Está diseñada para trabajar con grandes volúmenes de datos y procesarlos de forma extremadamente rápida. Su arquitectura OLAP permite hacer análisis complejos en tiempo real. Es ideal para casos donde se generan constantemente grandes cantidades de datos que luego deben ser consultados, agregados y visualizados. Algunos ejemplos típicos son contar cuántas personas visitan una web, desde qué lugares, qué páginas ven más, analizar cuántos errores ocurren en una aplicación o medir el rendimiento de un sistema en tiempo real.
El hecho de que sea una base de datos columnar le da una ventaja clave en el rendimiento. En lugar de almacenar los datos por filas, como hacen las bases de datos tradicionales, ClickHouse almacena los datos por columnas. Esto significa que cuando se hace una consulta, solo se accede a las columnas necesarias. Esto reduce el volumen de datos leídos, mejora la compresión y acelera enormemente operaciones como filtros, ordenamientos y agregaciones. Además, permite explotar al máximo el paralelismo y el uso de CPU y memoria, lo que lo hace muy eficiente incluso con conjuntos de datos gigantes. Algunos ejemplos de consultas para las que está preparada sería:
1. Contar cuántas visitas hubo hoy
SELECT COUNT(*) FROM visitas WHERE fecha = today()
2. Sumar las ventas de un producto
SELECT SUM(ventas) FROM ventas WHERE producto_id = 123
3. Contar cuántos errores hubo la semana pasada
SELECT COUNT(*) FROM errores WHERE fecha >= today() - 7
4. Ver cuántas visitas hubo por país
SELECT pais, COUNT(*) FROM visitas GROUP BY pais
Es una base de datos distribuida, lo que significa que puede funcionar en varios servidores al mismo tiempo. Esto le permite manejar aún más datos y procesarlos más rápido, ya que divide el trabajo entre varias máquinas. Gracias a esta arquitectura, ofrece una gran escalabilidad, facilitando que el sistema crezca según las necesidades sin perder rendimiento.
Usos comunes de ClickHouse
- Dashboards en tiempo real: Ver datos actualizados al instante, como el número de usuarios conectados o ventas del día. Esto ayuda a tomar decisiones rápidas basadas en la información más reciente.
- Análisis en tiempo real: Permite analizar eventos o comportamientos en el momento en que ocurren, como detectar picos de tráfico o patrones inusuales.
- Inteligencia de negocio (Business Intelligence): Se utiliza para generar informes y resúmenes que ayudan a entender el desempeño de una empresa, identificar tendencias y planificar estrategias, facilitando la toma de decisiones basadas en datos.
- Capa rápida para data warehouse: Funciona como una capa que procesa datos muy rápido dentro de un sistema de almacenamiento más grande, acelerando consultas sin afectar la base de datos principal.
- Registro de eventos y métricas: Almacena grandes volúmenes de registros de sistemas, aplicaciones o sensores, facilitando el monitoreo, detección de fallos y análisis de rendimiento.
- Machine Learning y ciencia de datos: Puede servir para preparar y analizar grandes conjuntos de datos que luego se usan en modelos de aprendizaje automático o para descubrir patrones y relaciones en los datos.
Instalación
Empezar con ClickHouse también es sencillo, teniendo en cuenta que ClickHouse funciona de forma nativa en Linux, FreeBSD y macOS, y en Windows a través del WSL, unicamente se deben poner los siguientes comandos:
1. Descargarlo con este comando: curl https://clickhouse.com/ | sh
2. Arrancar el servidor con: ./clickhouse server
3. En otra terminal arrancar el cliente con: ./clickhouse client
Además, si se desea un entorno gráfico, podemos usar clickhouse cloud (https://clickhouse.com/docs/cloud/get-started/sql-console)
Ejemplo básico de uso
Sintaxis básica de ClickHouse, se comienza creando una base de datos, una tabla y haciendo algunas inserciones y consultas.
CREATE DATABASE IF NOT EXISTS prueba_clickhouse;
USE prueba_clickhouse;
CREATE TABLE IF NOT EXISTS visitas (
id UInt64,
usuario_id UInt32,
pais String,
fecha Date,
paginas_vistas UInt32
) ENGINE = MergeTree()
ORDER BY fecha;
INSERT INTO visitas VALUES
(1, 101, 'España', '2025-06-01', 5),
(2, 102, 'México', '2025-06-01', 3),
(3, 103, 'Argentina', '2025-06-02', 7),
(4, 104, 'España', '2025-06-02', 2),
(5, 105, 'Colombia', '2025-06-03', 8);
SELECT pais, COUNT(*) AS visitas_totales
FROM visitas
GROUP BY pais
ORDER BY visitas_totales DESC;
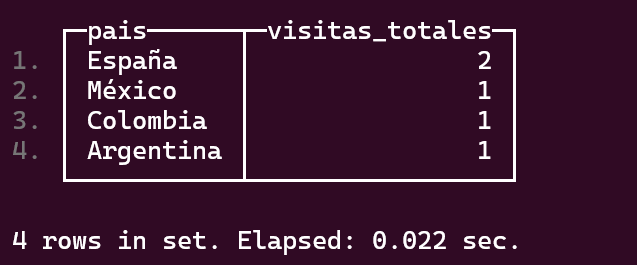
Ejemplo completo de uso
Cuando se trabaja con una base de datos ClickHouse, estan las opciones de almacenar dichos datos en nuestra base de datos almacenada en disco o trabajar de forma directa con otras fuentes de datos. ClickHouse ofrece integraciones con diferentes fuentes externas, como S3 de AWS, bases de datos como PostgreSQL, MySQL u ODBC, y sistemas de streaming como Kafka.
Para trabajar con datos en S3, existen dos opciones: leer directamente desde la fuente, o importar los datos a una tabla de nuestra base de datos en ClickHouse y luego consultarlos. A continuación mostramos ambos casos:
Si queremos algunos datasets de ejemplo podemos consultar en la documentación oficial de ClickHouse en el apartado “Example Datasets” (https://clickhouse.com/docs/getting-started/example-datasets)
Para este ejemplo vamos a consultar datos sobre los taxis de Nueva York en 2015
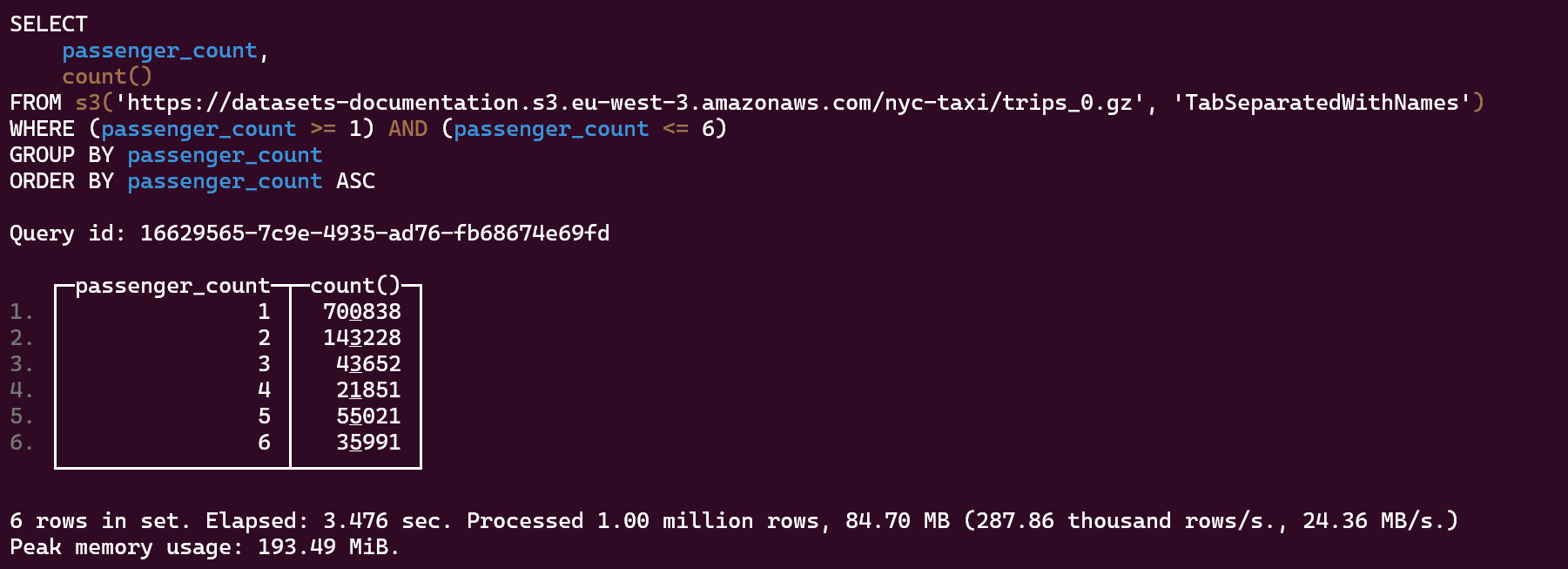
1- Lectura de datos de S3:
Número total de viajes por número de pasajeros
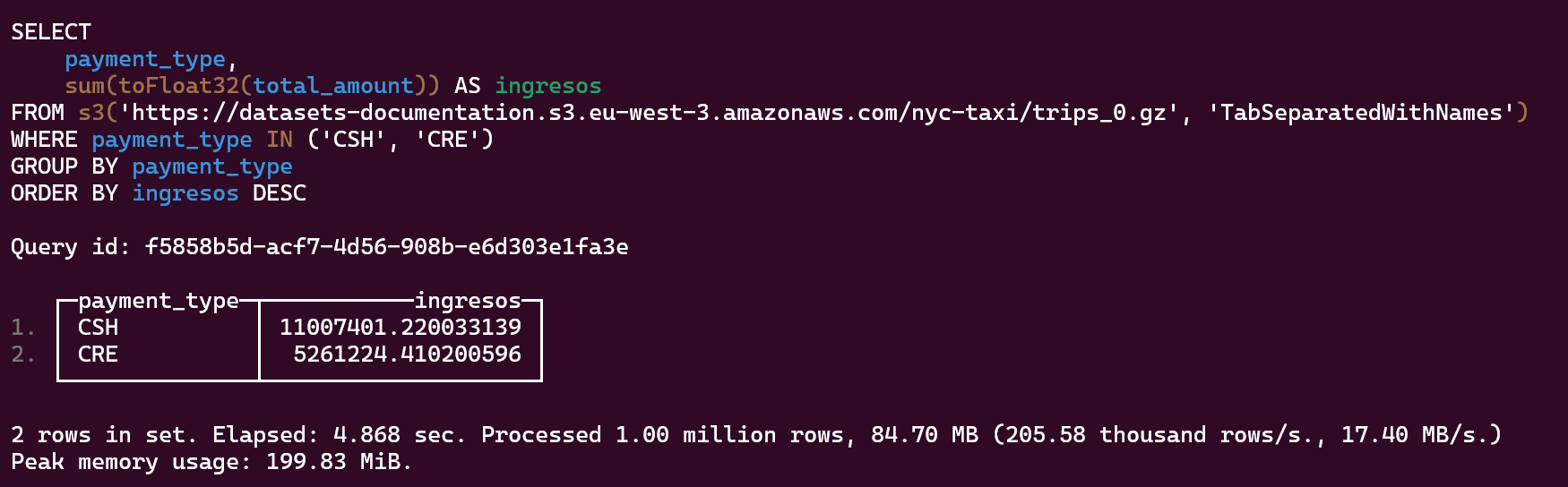
Total de dinero obtenido mediante efectivo o tarjeta de crédito
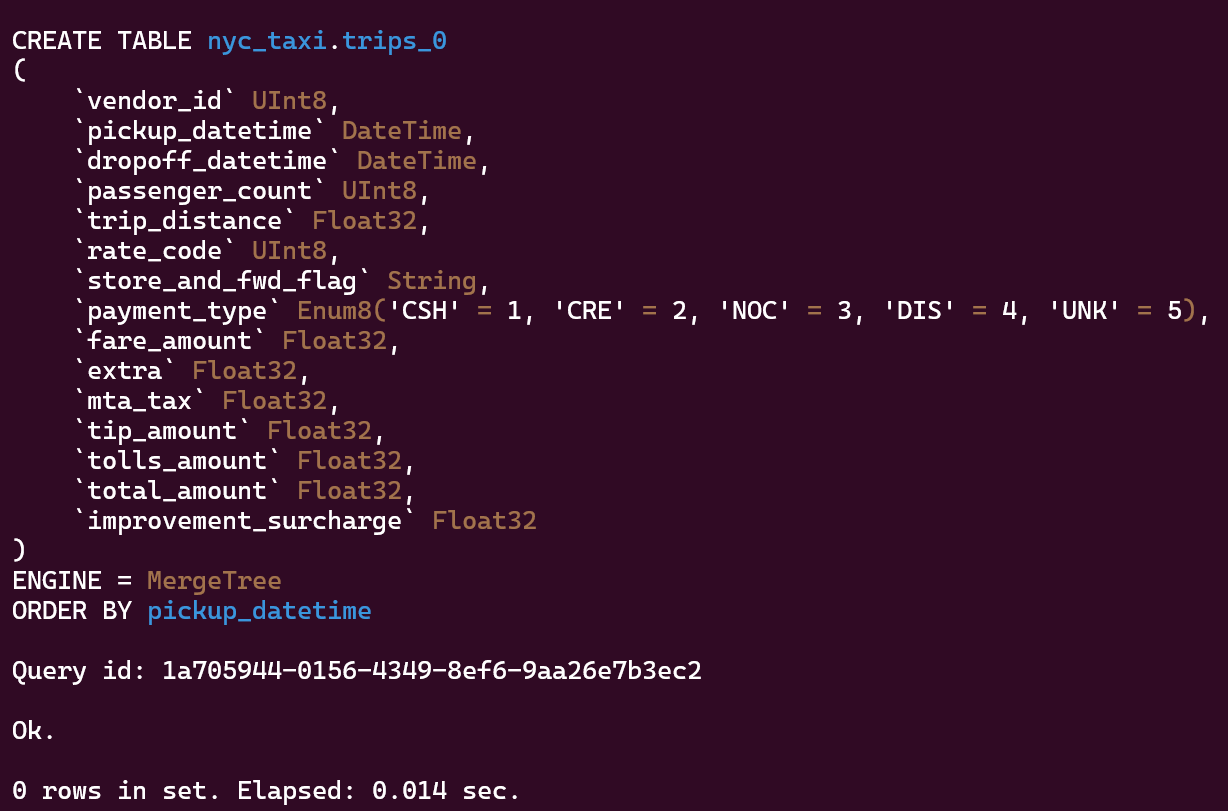
2- Crear tabla con datos de S3 y después consultarlos:
Ahora realizamos las mismas consultas que hemos realizado antes pero sobre estas tablas locales:
Número total de viajes por número de pasajeros
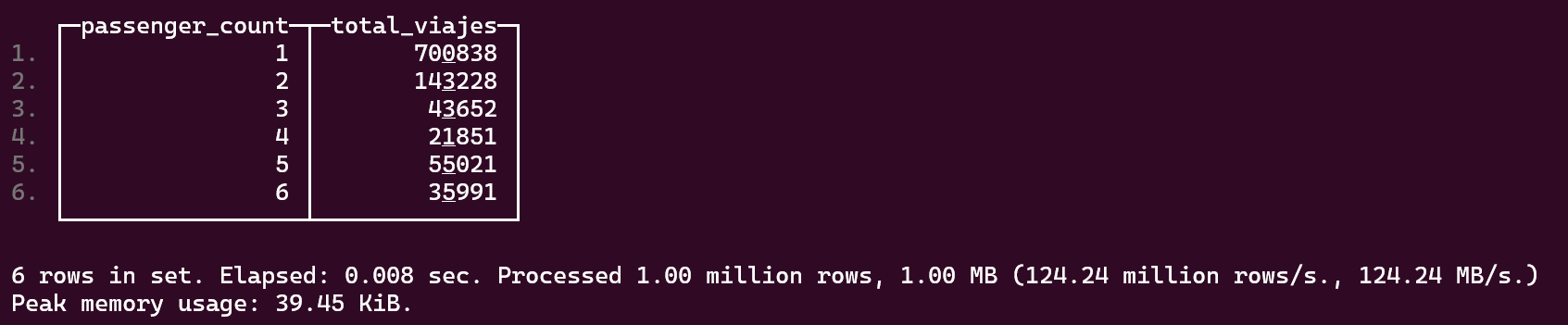
Total de dinero obtenido mediante efectivo o tarjeta de crédito

Tener las tablas en disco reduce claramente los tiempos de respuesta porque los datos están almacenados directamente en el servidor donde se ejecutan las consultas, evitando la latencia de red y posibles cuellos de botella al acceder a fuentes externas. Esto mejora mucho la velocidad y la eficiencia en análisis y agregaciones.
Almacenar grandes volúmenes de datos localmente consume un ligero espacio en disco y puede requerir mayor capacidad de hardware, mientras que consultar datos desde servicios externos (como S3) ahorra espacio local pero suele ser más lento y depende de la conexión de red, dependiendo de las necesidades del proyecto podemos emplear una forma u otra de trabajo.
Motores de ClickHouse (Engine)
En ClickHouse, un motor de almacenamiento (o engine) define cómo se almacenan y acceden los datos en una tabla. Cada tabla necesita un motor, y según el motor que elijas, tendrás diferentes funcionalidades, rendimiento y comportamiento. Es un concepto fundamental, porque el motor
determina si los datos se almacenan en disco, se leen desde una fuente externa, o se procesan de otra manera.
- MergeTree:Este es el motor más usado y versátil en ClickHouse. Guarda los datos físicamente en disco, y permite indexación por columnas, compresión automática y buen rendimiento en consultas masivas y agregaciones.
- S3:Este motor no guarda datos en local, lee directamente archivos alojados en algún bucket de S3 (Amazon Simple Storage Service). Es útil cuando los datos ya están almacenados en la nube y no se necesita importar previamente a una tabla física.
- Otros motores
Log / TinyLog: Motores simples, almacenan datos en orden de inserción. Útiles para pruebas o casos muy básicos.
•ExternalTable: Tablas temporales para consultas externas (como subconsultas con IN).
•View / MaterializedView: Para crear vistas normales o vistas materializadas (con datos precalculados).
•Kafka: Permite consumir datos en tiempo real desde tópicos de Kafka.
•MySQL / PostgreSQL: Motores que permiten crear tablas que leen datos directamente desde una base de datos externa (MySQL o PostgreSQL), útil para integraciones sin replicar datos.
Otras curiosidades sobre el funcionamiento de ClickHouse
- Particiones y segmentos: Las tablas MergeTree dividen los datos en particiones, normalmente por fecha (PARTITION BY), y dentro de estas, se crean segmentos ordenados (ORDER BY). Esto facilita eliminar y leer datos por rangos de tiempo y acelera mucho las búsquedas con filtros en columnas clave.
- Clave primaria: ClickHouse no tiene índices como MySQL, pero usa la clave primaria para ordenar los datos en disco. Esta clave ayuda a saltar grandes bloques de datos que no coinciden con el filtro y hacer consultas de rango mucho más eficientes. No garantiza unicidad, es solo para orden y búsqueda rápida.
- Compresión automática:ClickHouse comprime los datos por defecto (LZ4, ZSTD, etc.). Esto reduce mucho el tamaño en disco y permite leer más datos en menos tiempo.
- Lectura paralela:ClickHouse lee en paralelo usando todos los núcleos de CPU posibles. Divide los datos en partes y los procesa de forma simultánea, lo que da un gran boost de rendimiento.
Ejemplos de conexiones ClickHouse con PostgreSQL o MySQL
SELECT * FROM postgresql( 'localhost:5432', 'my_database', 'my_table', 'postgresql_user', 'password');
SELECT * FROM mysql( 'localhost:3306', 'my_database', 'my_table', 'postgresql_user', 'password');
Comparativa de rendimientos
10 Millones de filas:

El ejemplo anterior, se ha creado una tabla con 3 columnas, las mismas condiciones para ambas bases de datos, y la consulta de lectura es “SELECT count(*) from muchos_datos;”
Como podemos apreciar de forma clara, el rendimiento de lectura y escritura en ClickHouse es muy superior al rendimiento en PostgreSQL debido a las características principales de la base de datos.
El hecho de que en la inserción tarde menos tiempo es porque ClickHouse acumula las filas por bloques y mete directamente los bloques, esto hace que sea mas rápida la escritura en lugar de escribir muchas filas individualmente. Además ClickHouse no escribe en el WAL cada operación, cosa que otras bases de datos sí hacen. Por último, una de las cosas que hace que la inserción sea mas rápida es que el almacenamiento de forma interna se hace por columnas y de forma comprimida.
Posibilidad de integración en Kubernetes
ClickHouse se puede integrar perfectamente en Kubernetes para aprovechar su escalabilidad, despliegue automatizado y gestión de recursos. Algunas ideas clave de lo que puedes hacer con ClickHouse dentro de un entorno Kubernetes son:
- Despliegue automatizado: Puedes desplegar ClickHouse fácilmente como un StatefulSet, usando Helm charts oficiales o personalizados. Esto permite tener nodos con almacenamiento persistente y configuración consistente.
- Escalabilidad horizontal: En Kubernetes puedes escalar ClickHouse añadiendo más réplicas de nodos, tanto para lectura como escritura, y distribuir los datos entre ellos. Esto es especialmente útil en cargas analíticas pesadas.
- Alta disponibilidad: Combinando ClickHouse con servicios como Zookeeper y replicación interna, puedes tener un cluster distribuido con tolerancia a fallos y failover automático dentro del clúster de Kubernetes.
- Integración con microservicios: Puedes tener microservicios que hagan consultas o inserciones a ClickHouse directamente desde otros pods.
- Monitorización y métricas: Puedes usar Prometheus + Grafana para monitorizar ClickHouse desde Kubernetes, ya que expone métricas HTTP. Esto ayuda a tener control del rendimiento y detectar cuellos de botella.
- Configuración de almacenamiento eficiente: Puedes asignar volúmenes persistentes (PVC) rápidos y grandes para los datos, y aprovechar el control fino de Kubernetes para balancear rendimiento y coste.
Conclusión
ClickHouse destaca por su excelente rendimiento al procesar grandes volúmenes de datos en tiempo récord, lo que lo hace especialmente útil en escenarios donde la velocidad de consulta es crítica. Es una gran elección cuando se necesita obtener métricas, agregaciones o análisis complejos casi en tiempo real, como en sistemas de monitoreo, analítica de usuarios, procesamiento de logs, etc.
Su eficiencia lo convierte en una opción muy útil cuando otras bases de datos relacionales se quedan cortas en tiempos de respuesta frente a datasets masivos. Además, encaja muy bien en entornos modernos y distribuidos, gracias a su capacidad de integrarse con otras fuentes y funcionar de forma
escalable en la nube o en Kubernetes. Por tanto, usar ClickHouse tiene mucho sentido cuando el objetivo está en la velocidad de lectura, el análisis masivo y la escalabilidad.
¿Quieres saber más sobre Hunters?
Ser un hunter es aceptar el reto de probar nuevas soluciones que aporten resultados diferenciales. Únete al programa Hunters y forma parte de un grupo transversal con capacidad de generar y transferir conocimiento.
Anticípate a las soluciones digitales que nos harán crecer. Consulta más información sobre Hunters en la web.

Francisco Fernández
Técnico de Software
Altia